SpringCloud微服务基础
SpringCloud
导学
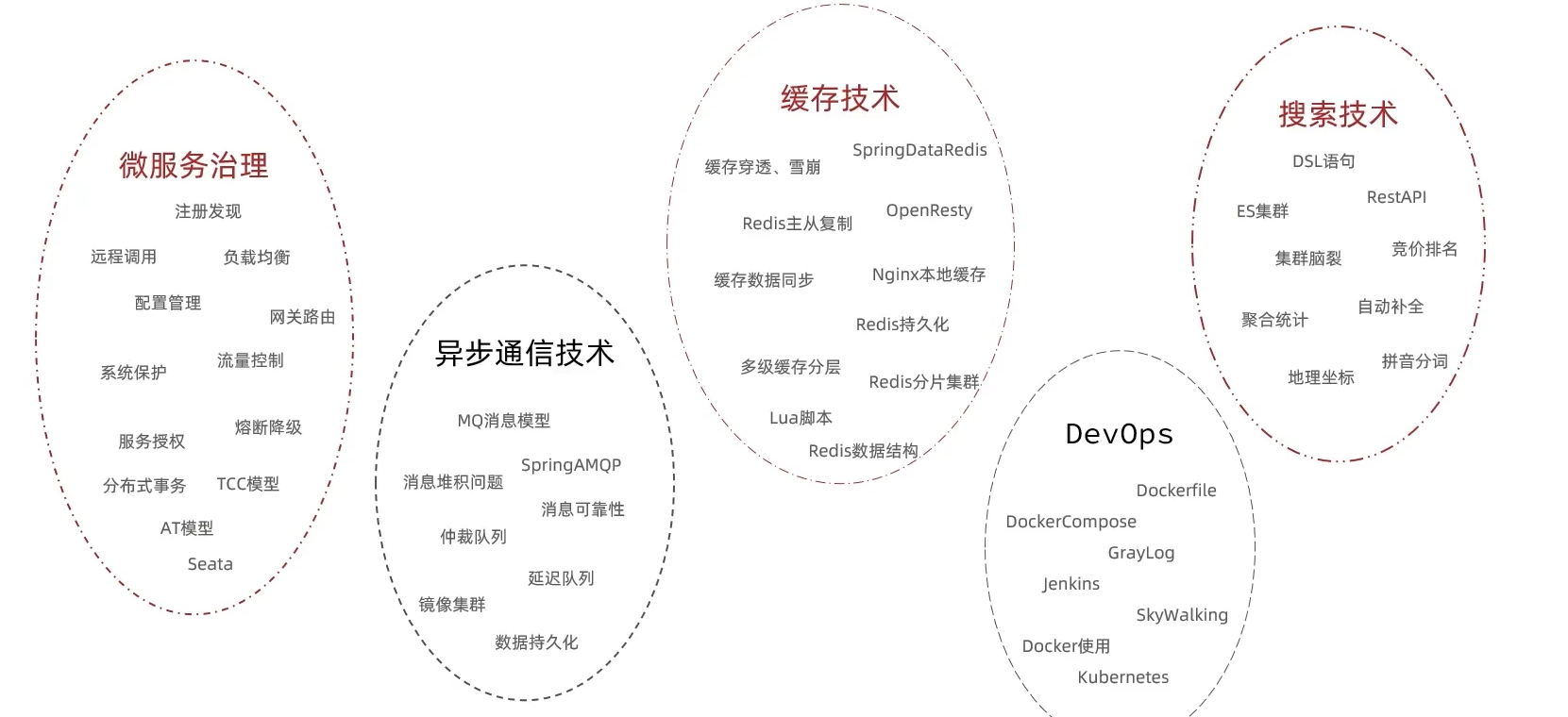
微服务技术栈:

概念
架构
- 单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署
- 优点:
- 架构简单
- 部署成本低
- 缺点:
- 耦合度高
- 优点:
- 分布式架构:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务
- 优点:
- 降低耦合度
- 有利于服务升级拓展
- 缺点:
- 要考虑服务治理
- 服务拆分粒度如何?
- 服务集群地址如何维护?
- 服务之间如何实现远程调用?
- 服务健康状态如何感知?
- 架构非常复杂:运维、监控、部署难度提高
- 要考虑服务治理
- 优点:
微服务:
微服务是一种经过良好架构设计的分布式架构方案
- 微服务架构的特征:

- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
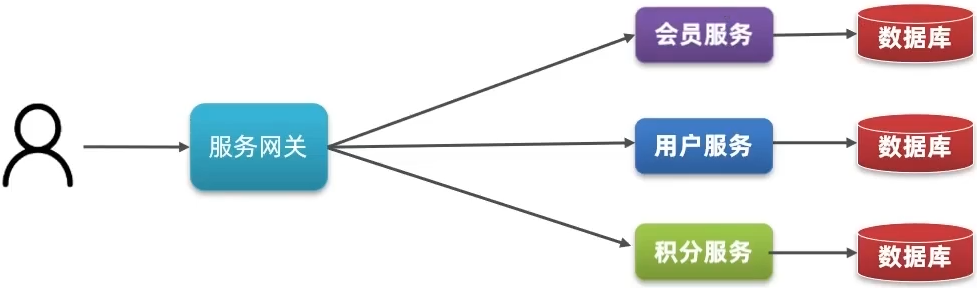
微服务结构
微服务这种方案需要技术框架来落地,国内最知名的就是SpringCloud和阿里巴巴的Dubbo
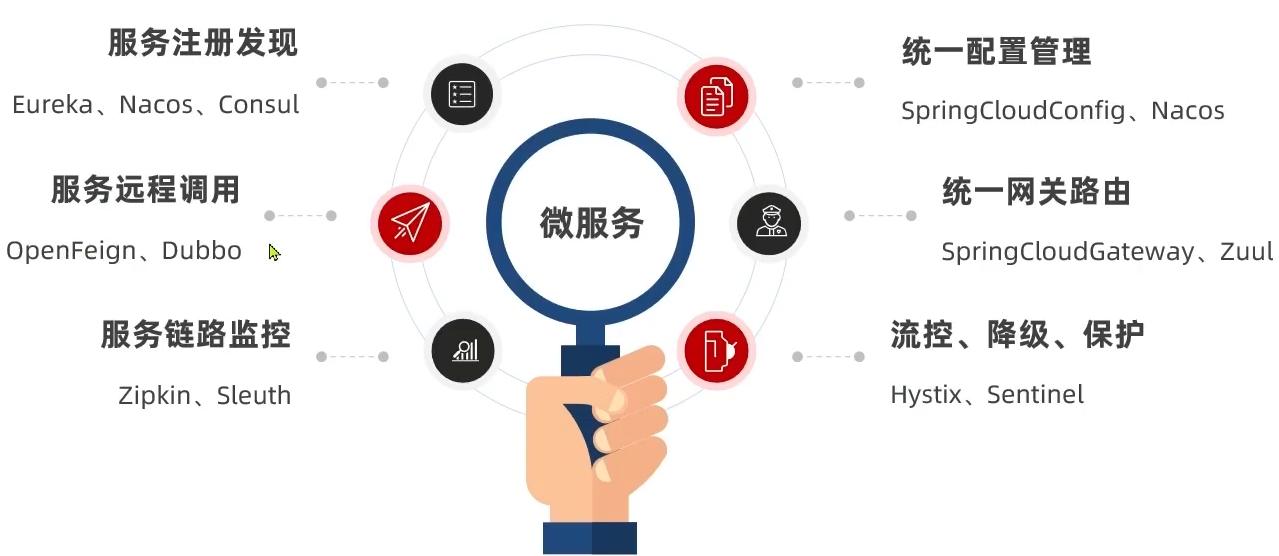
| Dubbo | SpringCloud | SpringCloudAlibaba | |
|---|---|---|---|
| 注册中心 | zookeeper、Redis | Eureka、Consul | Nacos、Eureka |
| 服务远程调用 | Dubbo协议 | Feign(http协议) | Dubbo、Feign |
| 配置中心 | 无 | SpringCloudConfig | SpringCloudConfig、Nacos |
| 服务网关 | 无 | SpringCloudGateway、Zuul | SpringCloudGateway、Zuul |
| 服务监控和保护 | dubbo-admin,功能弱 | Hystrix | Sentinel |
SpringCloud
- SpringCloud是目前国内使用最广泛的微服务框架
- SpringCloud继承了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验
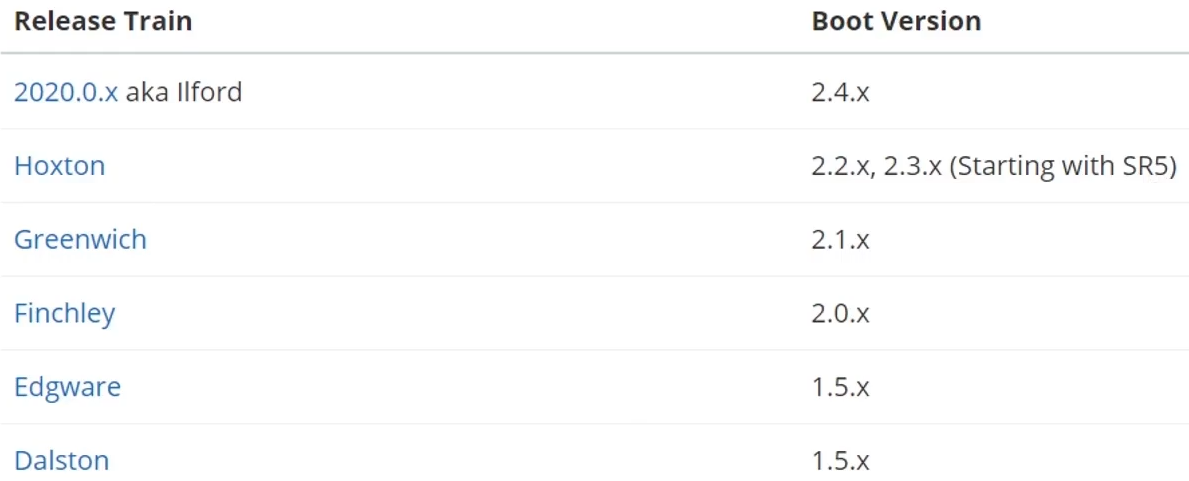
- SpringCloud与SpringBoot的版本兼容关系:(本教程使用Hoxton.SR10版本)
服务拆分
- 注意事项:
- 不同微服务,不要重复开发相同的业务
- 微服务数据独立,不要访问其他微服务的数据库
- 微服务可以将自己的业务暴露为接口,供其他微服务调用
微服务远程调用
注册RestTemplate为Bean
1
2
3
4//随意在配置类中注册Bean,建议在SpringBoot启动类
public RestTemplate restTemplate() {
return new RestTemplate();
}服务远程调用RestTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class OrderService {
private OrderMapper orderMapper;
private RestTemplate restTemplate; //注入此Bean
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.根据order对象的userId查询对应的用户信息,把userId发送到对应的url查询并封装
Long userId = order.getUserId();
User user = restTemplate.getForObject("http://localhost:8081/user/" + userId, User.class);
// 3.封装数据
order.setUser(user);
// 4.返回
return order;
}
}
调用方式:
- 基于RestTemplate发起http请求实现远程调用
- http请求做远程调用是与语言无关的调用,只需要知道对方的url(ip、端口、接口路径、请求参数)即可
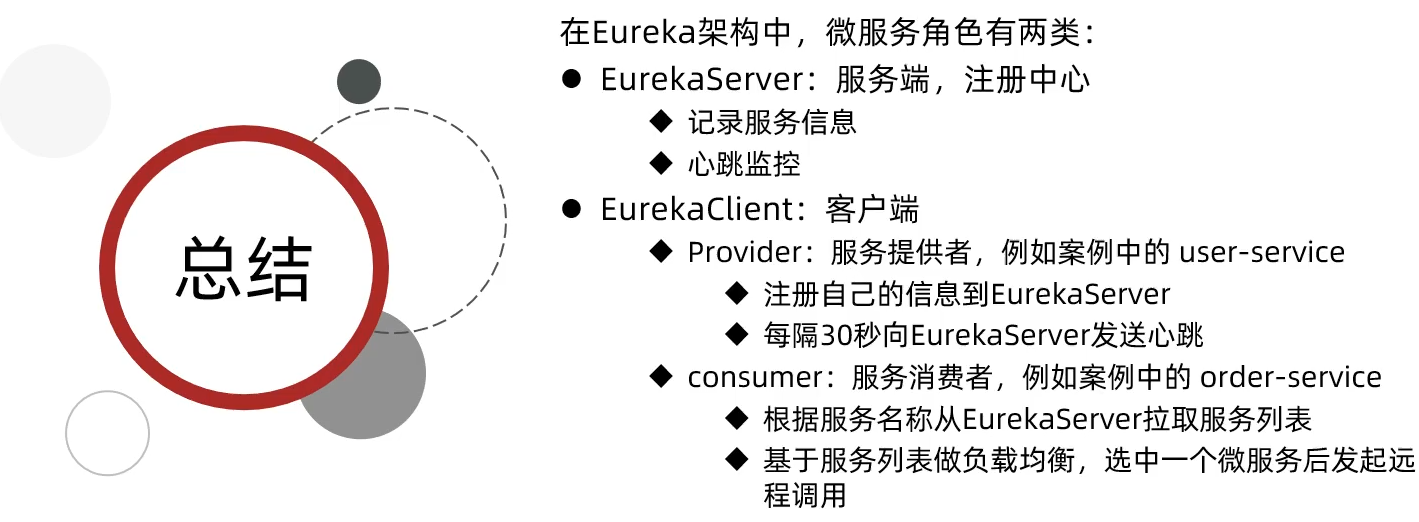
Eureka注册中心
提供者与消费者
- 服务提供者:一次业务中,被其他微服务调用的服务
- 服务消费者:一次业务中,调用其他微服务的服务
提供者与消费者角色是相对的,一个服务即可以是提供者,又可以是消费者
Eureka的作用
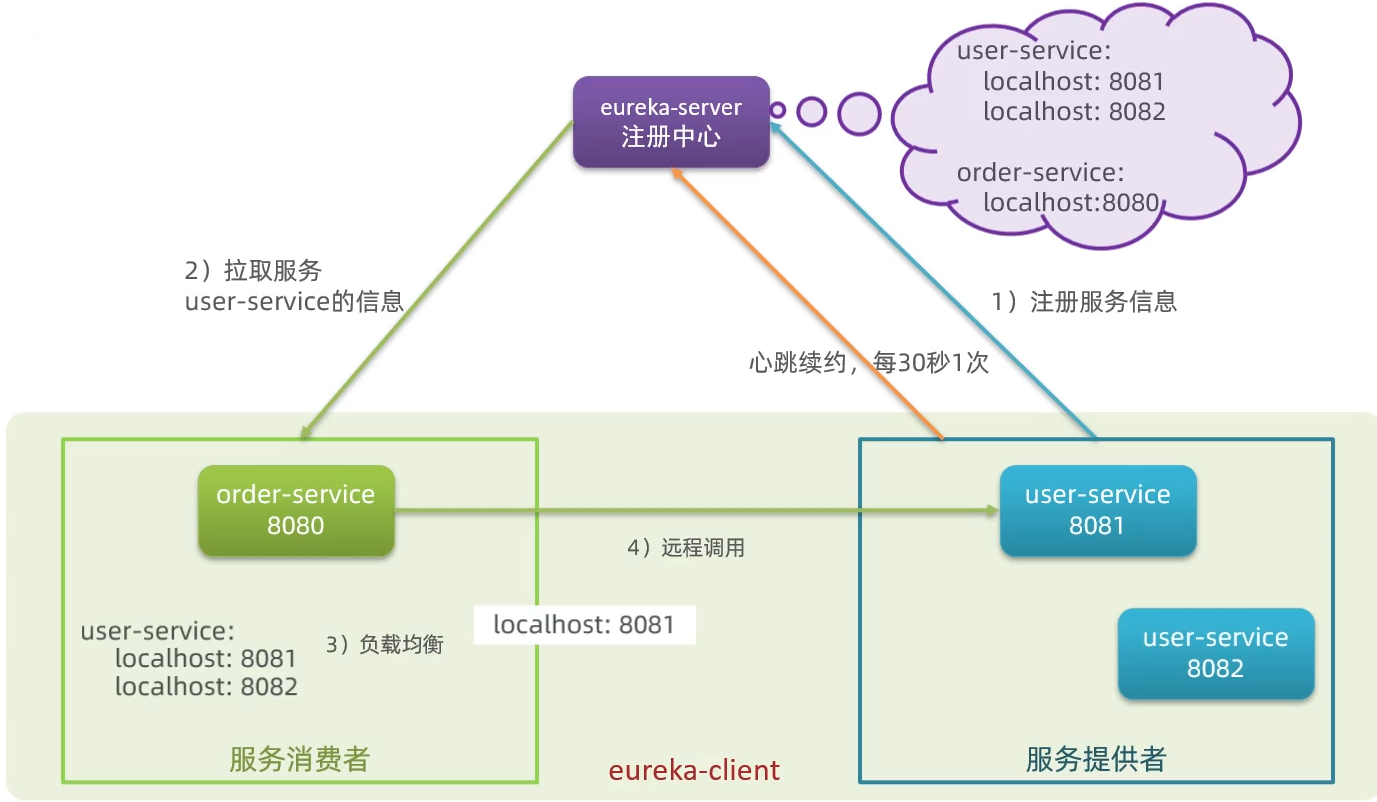
服务调用出现的问题
- 消费者如何获取提供者的具体信息?
- 服务提供者启动时向Eureka注册自己的信息
- Eureka保存这些信息
- 消费者根据服务名称向Eureka拉取提供者信息
- 如果有多个服务提供者,消费者该如何选择?
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
- 消费者如何感知服务提供者健康状态?
- 服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
- Eureka会更新记录服务列表信息,心跳不正常的会被剔除
- 消费者可以拉取到最新的信息
快速入门
1.搭建EurekaServer服务
创建项目,引入
spring-cloud-starter-netflix-eureka-server的依赖1
2
3
4
5
6<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>编写启动类,添加
@EnabledEurekaServer注解1
2
3
4
5
6
7
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}在SpringBoot核心配置文件配置Eureka服务端
1
2
3
4
5
6
7
8
9
10server:
port: 8082 # Eureka的SpringBoot服务端口
spring:
application:
name: eurekaserver # Eureka的服务名称
eureka:
client:
service-url:
defaultZone: http://localhost:8082/eureka # Eureka的地址信息
fetch-registry: false # 关闭从Eureka服务器获取信息
2.注册service到EurekaServer(服务注册)
在需要注册为Eureka客户端的项目中引入
spring-cloud-starter-netflix-eureka-client的依赖1
2
3
4
5
6<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>在SpringBoot核心配置文件中配置Eureka客户端
1
2
3
4
5
6
7spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://localhost:8082/eureka
3.拉取service从EurekaServer(服务发现)
服务拉取是基于服务名称获取服务列表,然后再对服务列表做负载均衡
修改service中要访问的url路径,用服务名代替ip、端口
1
2User user = restTemplate.
getForObject("http://userservice/user/" + userId, User.class);在service的启动类中产生@RestTemplate的Bean上打上@LoadBalanced负载均衡注解
1
2
3
4
5
public RestTemplate restTemplate() {
return new RestTemplate();
}
Ribbon负载均衡
负载均衡原理
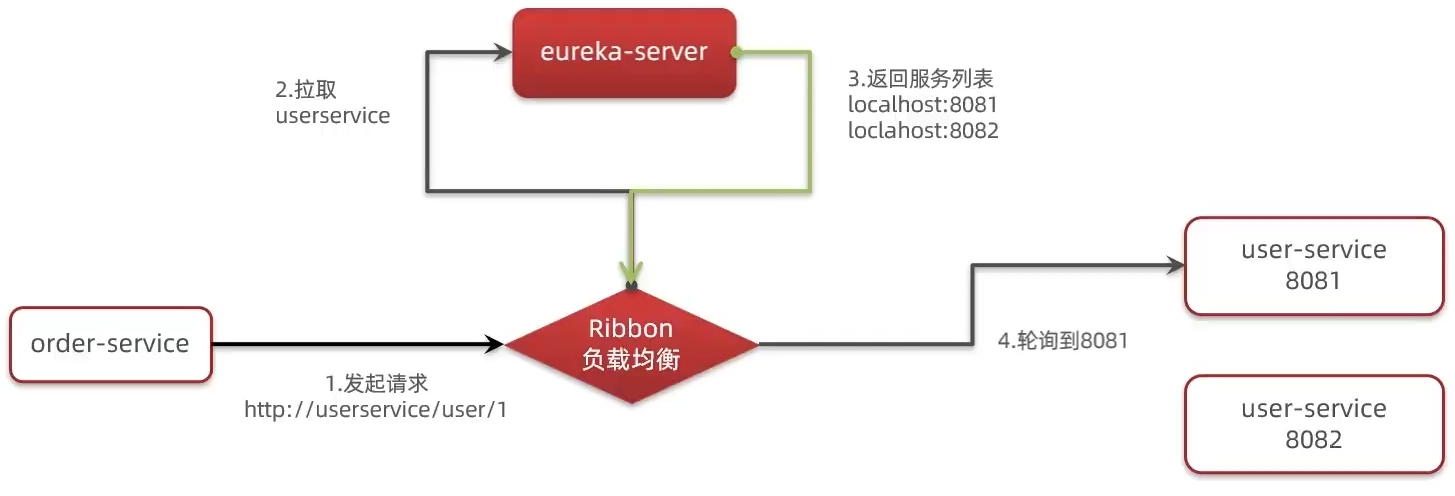
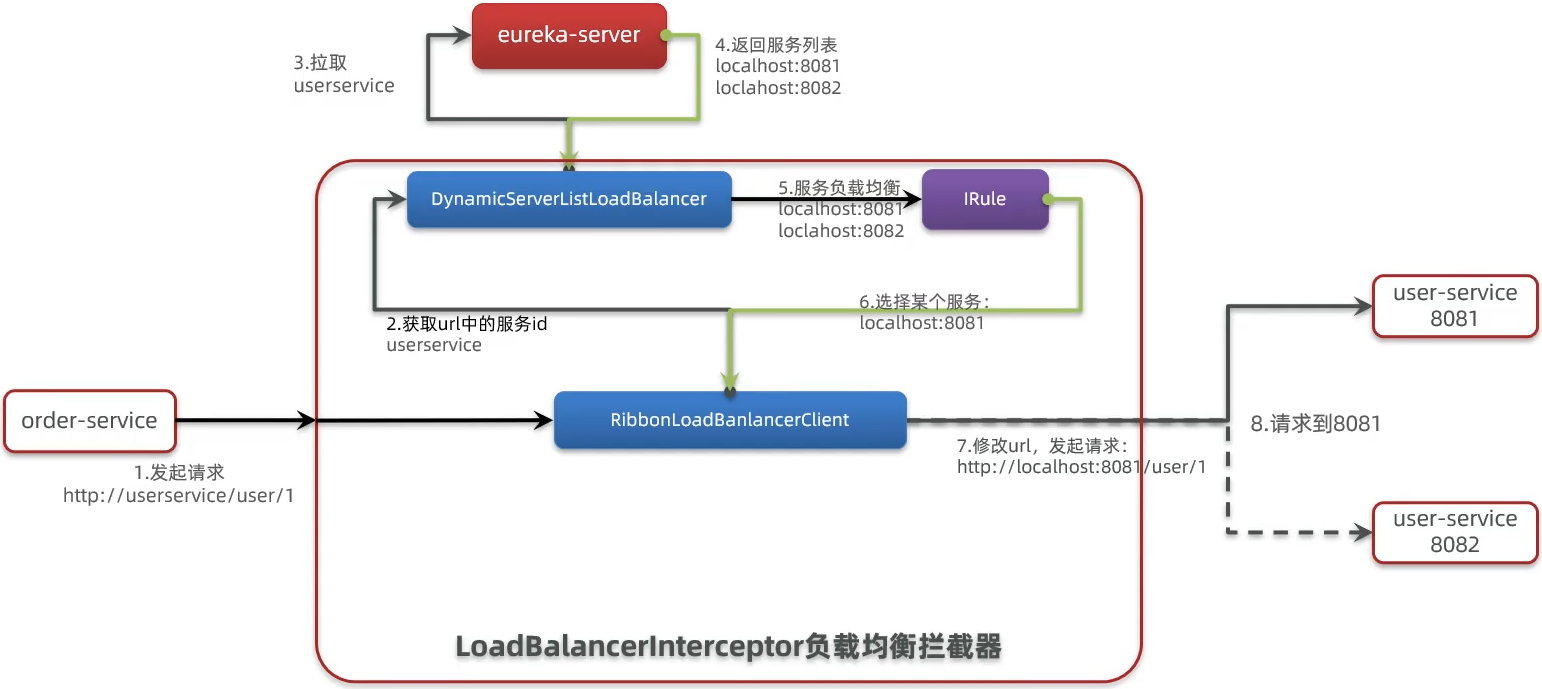
负载均衡策略

默认实现是ZoneAvoidanceRule,是一种轮询方案
通过定义IRule实现可以修改负载均衡规则,有两种方式:
代码方式:在service启动类中定义一个@Bean方法返回一个IRule实现类
1
2
3
4
public IRule randomRule() {
return new RandomRule();
}配置文件方式:在service所在的SpringBoot核心配置文件中配置规则
1
2
3userserivce:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡的规则
懒加载和饥饿加载
Ribbon默认采用懒加载,即第一次访问时才会创建LoadBalanceClient,请求时间会比较长
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时
开启饥饿加载:
1 | ribbon: |
Nacos注册中心
Nacos是阿里巴巴的产品,现在是SpringCloud的一个组件。相比Eureka功能更丰富
快速入门
1.安装Nacos
windows环境:
解压Nacos的zip包
启动Nacos安装目录下的bin目录下的startup.cmd
1
startup.cmd -m standalone
访问Nacos管理页面:默认用户名密码均为
nacos
docker环境
拉取nacos server的镜像
创建配置文件
1
2
3mkdir /home/nacos/init.d
mkdir /home/nacos/logs
vim /home/nacos/init.d/custom.properties配置文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30=/nacos
=/nacos
=8848
=mysql
=1
=jdbc:mysql://120.79.141.53:3307/nacos?#characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
=root
=123
=3600
=10
=300
=false
=false
=false
=true
=%h %l %u %t "%r" %s %b %D %{User-Agent}i
=/,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/v1/auth/login,/v1/console/health/**,/v1/cs/**,/v1/ns/**,/v1/cmdb/**,/actuator/**,/v1/console/server/**
=1
=200
=1000
=0.9
=5000
=true
=true启动容器
1
2
3
4
5
6
7
8
9
10
11
12docker run \
--name nacos -d \
-p 8848:8848 \
--privileged=true \
--restart=always \
-e JVM_XMS=128m \
-e JVM_XMX=128m \
-e MODE=standalone \
-e PREFER_HOST_MODE=hostname \
-v /home/nacos/logs:/home/nacos/logs \
-v /home/nacos/init.d/custom.properties:/home/nacos/init.d/custom.properties \
nacos/nacos-server
2.服务注册与发现
在父工程添加spring-cloud-alibaba的管理依赖
1
2
3
4
5
6
7
8
9<dependencyManagement>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>去掉service的Eureka依赖
添加Nacos的客户端依赖
1
2
3
4
5
6
7
8
9
10
11
12<dependencies>
<!--Eureka客户端依赖-->
<!--<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>-->
<!--nacos依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
</dependencies>在service的SpringBoot核心配置文件中配置nacos的地址
1
2
3
4spring:
cloud:
nacos:
server-addr: localhost:8848 #nacos的服务地址,默认

3.服务集群属性
修改service的SpringBoot核心配置文件
1
2
3
4
5spring:
cloud:
nacos:
discovery:
cluster-name: shanghaiNacos控制台可以查看集群
4.NacosRule服务集群优先级
配置负载均衡的规则为NacosRule:
- java配置
1 |
|
- service的SpringBoot核心配置文件中配置
1 | userserivce: |
NacosRule的规则如下:
- 优先选择同集群的服务实例列表
- 本地集群找不到提供者,才会去其他集群寻找,并且会报警告
- 确定了可用实例列表后,再采用随机负载均衡挑选实例
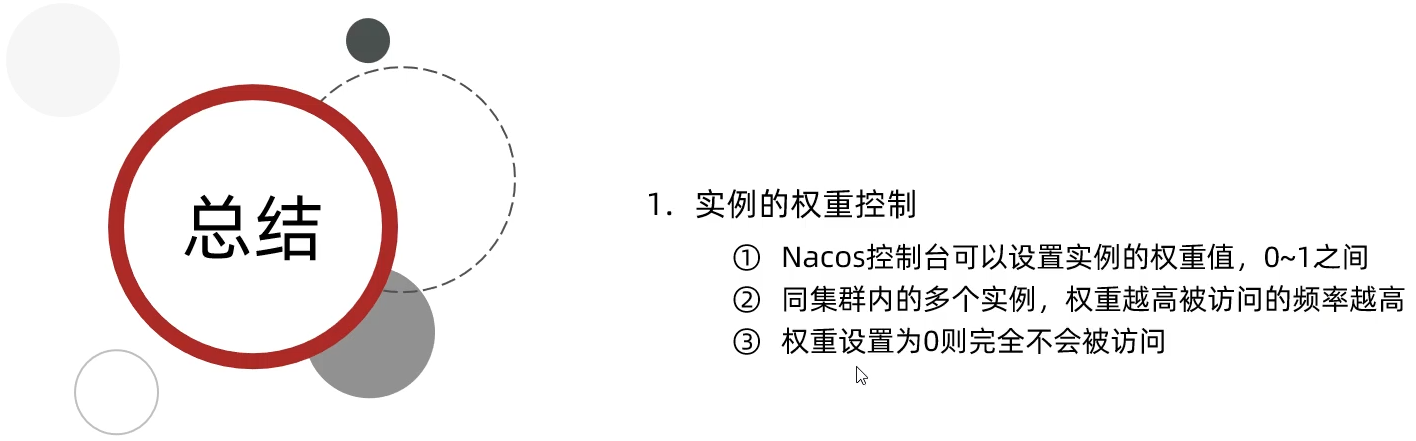
5.根据权重负载均衡
在Nacos控制台设置实例的权重值
设置此实例的权重(取值[0,1]之间):
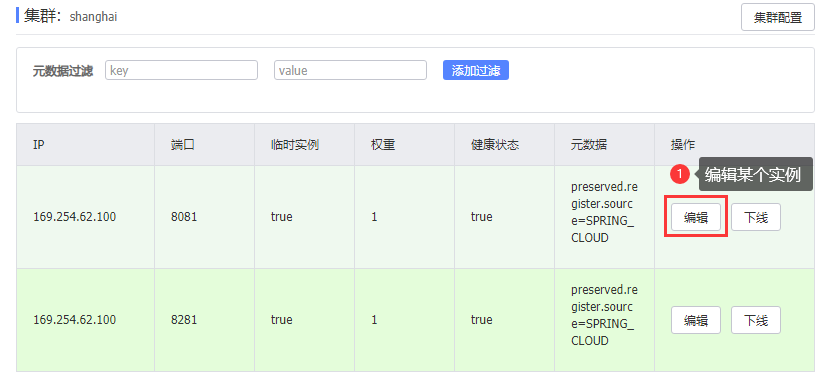
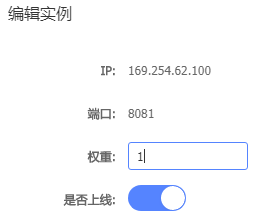
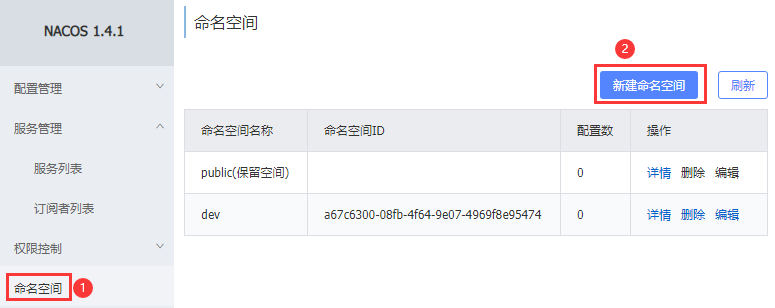
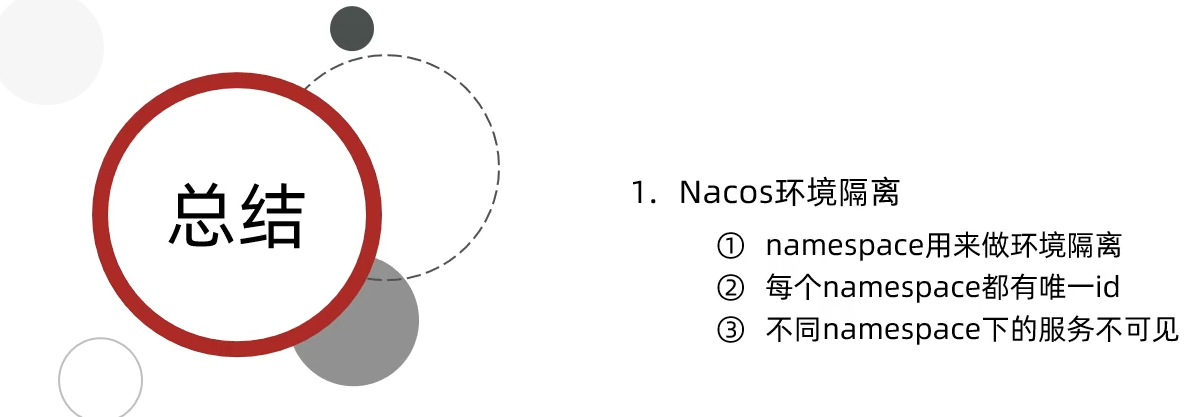
6.环境隔离namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离
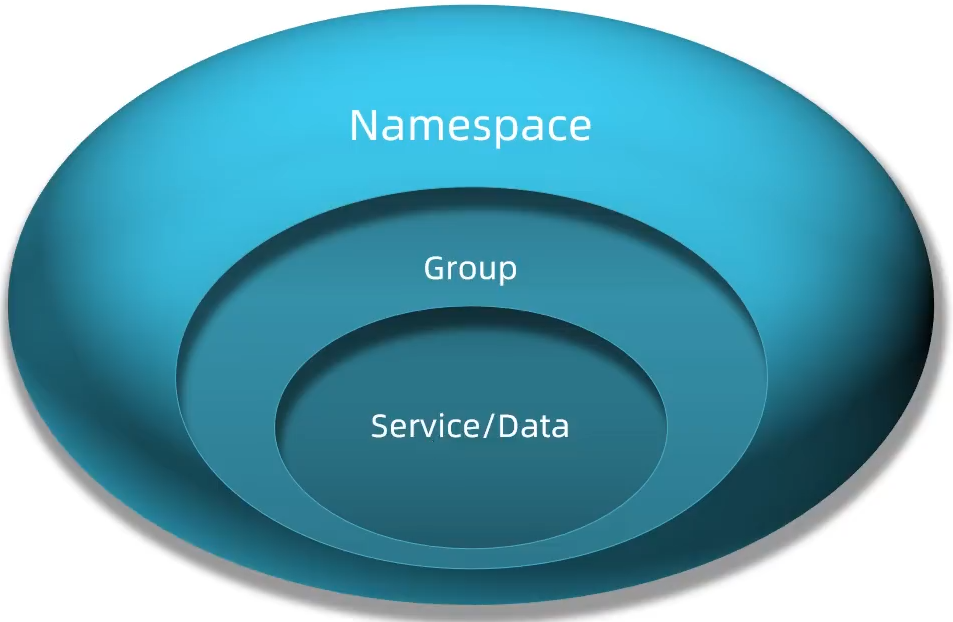
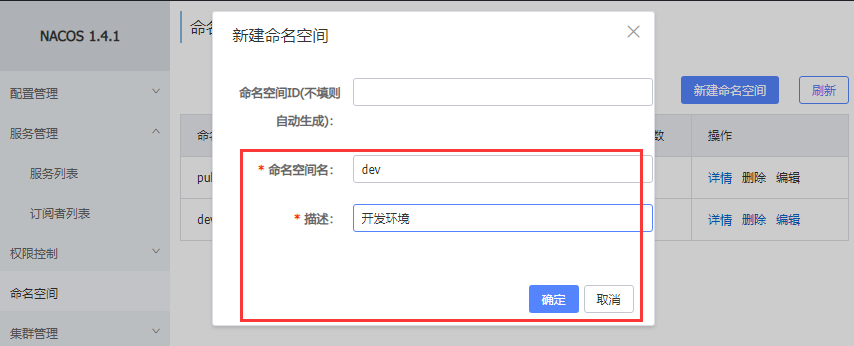
在Nacos控制台创建namespace,用来隔离不同环境
填写namespace信息
上述步骤之后会生成一个命名空间以及id
修改service的SpringBoot核心配置文件,添加namespace
1
2
3
4
5
6
7
8
9spring:
application:
name: orderservice
cloud:
nacos:
server-addr: localhost:8848 #nacos的服务地址
discovery:
cluster-name: hangzhou
namespace: a67c6300-08fb-4f64-9e07-4969f8e95474 #命名空间的id此时启动service会导致此service位于指定的命名空间下
访问此orderservice由于namespace不同,会导致找不到userservice

Nacos注册中心细节分析
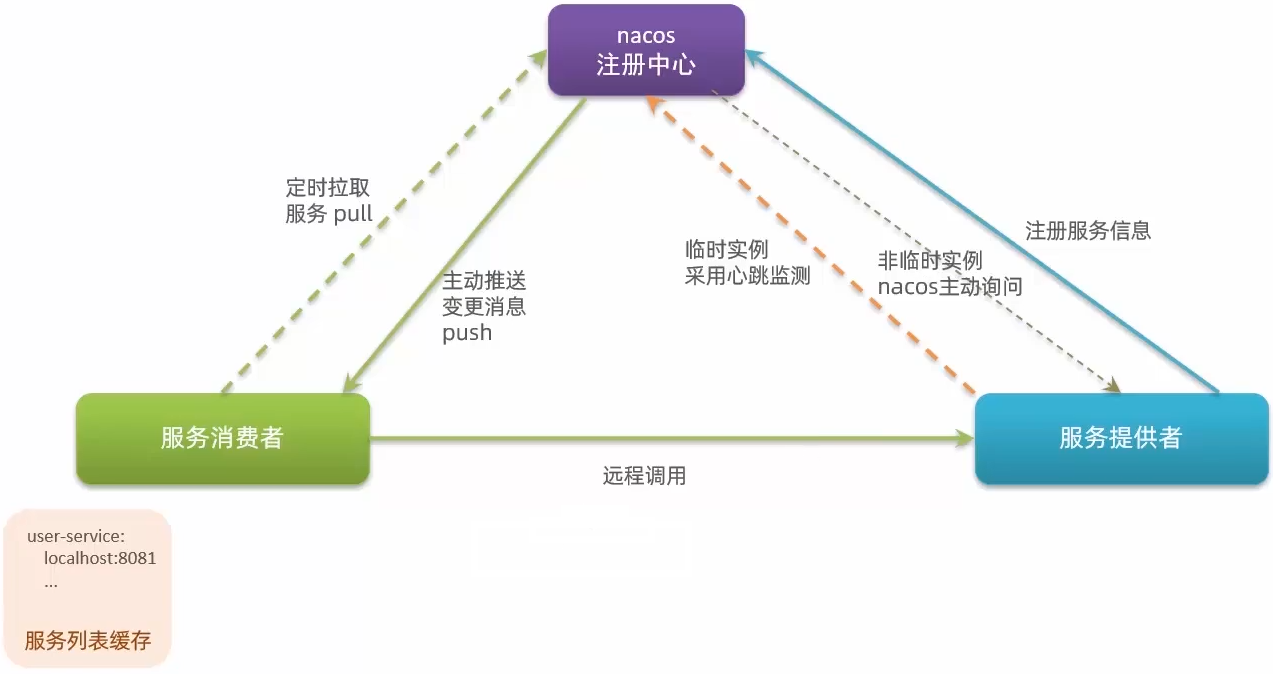
临时实例和非临时实例
服务注册到Nacos时,可以选择临时实例或非临时实例,通过配置SpringBoot核心配置文件:
1 | spring: |

Nacos配置管理
配置Nacos配置
在Nacos管理页面添加配置
填写配置信息
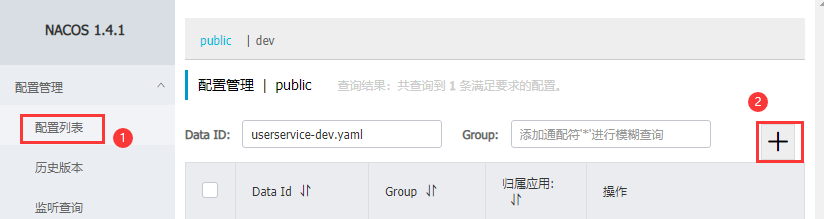
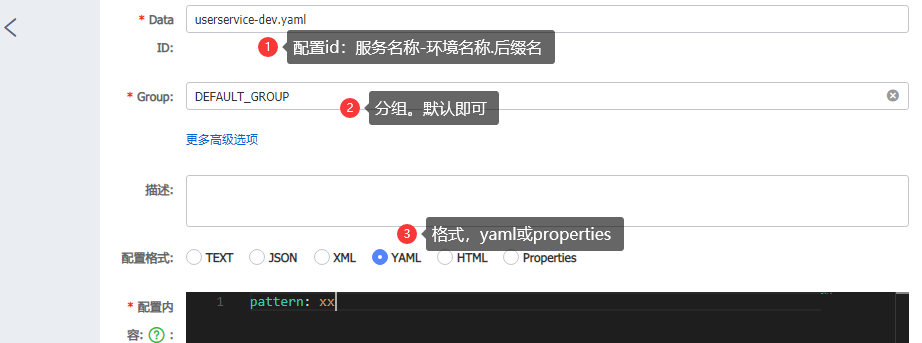
读取Nacos配置
引入Nacos的配置管理客户端依赖
1
2
3
4
5<!--nacos的配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>在service的resources目录中添加一个bootstrap.yml引导文件,优先级高于application.yml
1
2
3
4
5
6
7
8
9
10spring:
application:
name: userservice #服务名
profiles:
active: dev #配置环境名
cloud:
nacos:
server-addr: localhost:8848 #nacos地址
config:
file-extension: yaml #配置文件后缀名读取Nacos配置信息
1
2
3
4
5
6
7
private String dateFormat;
public String getNow() {
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateFormat));
}

热更新Nacos配置
Nacos中的配置文件变更后,微服务无需重启就可以感知。不过需要下面两种配置实现:
方式一:在@Value注入的变量所在的类上打上
@RefreshScope注解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class UserController {
private UserService userService;
private String dateFormat;
public String getNow() {
return LocalDateTime.now().
format(DateTimeFormatter.ofPattern(dateFormat));
}
}方式二:使用
@ConfigurationProperties注解读取配置文件到配置类中,然后从配置类取得配置项的值读取到配置类中,并标记此配置类是一个Bean以方便其他地方注入使用
1
2
3
4
5
6
public class PatternProperties {
private String dateFormat;
}注入配置类Bean并使用配置项的值
1
2
3
4
5
6
7
8
private PatternProperties properties; //注入配置类的Bean
public String getNow() {
return LocalDateTime.now().
format(DateTimeFormatter.ofPattern(properties.getDateFormat()));
}注意:这种方式不需要
@RefreshScope注解

多环境配置共享
微服务在启动时会从Nacos读取多个配置文件
- [spring.application.name]-[spring.profiles.active].yaml,例如userservice-dev.yaml
- [spring.application.name].yaml,例如userservice.yaml。这种情况下与环境无关
无论环境如何变化,[spring.application.name]不会变化,所以[spring.application.name].yaml一定会加载
服务名.yaml可以被所有spring.application.name相同的服务读取到,属于共享配置
多种配置优先级:在本地application.yml、Nacos配置的某环境yaml、Nacos配置的通用共享yaml中:
服务名-环境名.yaml > 服务名.yaml > 本地配置.yaml

Nacos集群
1.Nacos集群结构图
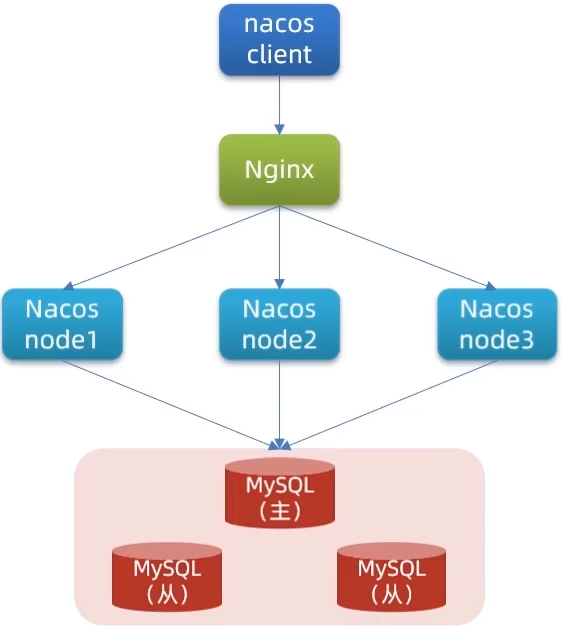
2.搭建集群:步骤
搭建数据库集群,初始化数据库表结构
- Nacos默认数据存储在内嵌的Derby数据库中,不属于生产可用的数据库
- 官方推荐的最佳实践是使用带有主从的高可用数据库集群,主从模式的高可用数据库自学
- 这里以单点的数据库为例:
- 新建一个数据库,命名为nacos
- 导入nacos建表有关SQL(注意字段为datetime类型赋默认值需要MySQL5.6版本以上)
下载nacos安装包
配置nacos
配置nacos安装目录下的
conf目录下的cluster.conf,设置集群的节点1
2
3127.0.0.1:8845
127.0.0.1.8846
127.0.0.1.8847配置nacos安装目录下的
conf目录下的application.properties,配置数据库1
2
3
4
5
6
7
8
9#*************** Config Module Related Configurations ***************#
### If use MySQL as datasource:
=mysql
### Count of DB:
=1
### Connect URL of DB:
=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
=root
=199988配置多个nacos服务器的端口(8845、8846、8847)
1
2### Default web server port:
=8845JVM内存不够的问题!
配置nacos安装目录下的
bin目录下的启动脚本,修改cluster模式下的JVM参数1
2
3
4
5
6
7
8rem if nacos startup mode is cluster
if %MODE% == "cluster" (
echo "nacos is starting with cluster"
if %EMBEDDED_STORAGE% == "embedded" (
set "NACOS_OPTS=-DembeddedStorage=true"
)
set "NACOS_JVM_OPTS=-server -Xms512m -Xmx512m -Xmn256m 后面省略了
)
启动nacos集群
- 直接运行
startup.cmd不需要再设置以单击启动的参数了
- 直接运行
配置nginx反向代理
编辑nginx安装目录下的
conf目录,在http标签内部加入nginx配置:1
2
3
4
5
6
7
8
9
10
11
12upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}启动nginx
- 直接运行
start nginx.exe - 停止nginx:
nginx.exe -s stop或者nginx.exe -s quit,建议用quit优雅退出
- 直接运行
访问
http:localhost:80/nacos即可代理到nacos-cluster所定义的几个负载均衡结点上
3.测试Nacos集群
- 访问
http:localhost:80/nacos会被代理到负载均衡的节点上 - 在Nacos管理页面创建配置会保存到本地MySQL的
config_info数据库中
Feign远程调用
RestTemplate方式调用存在的问题
1 | User user = restTemplate. |
- 代码可读性差,编程体验不统一
- 参数复杂时URL难以维护
Feign的概念
Feign是一个声明式的http客户端,其作用就是帮助我们优雅的实现http请求的发送,解决以上的问题
快速入门
引入起步依赖
1
2
3
4
5<!--Feign客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>在service的启动类上添加
@EnableFeignClients注解开启Feign的功能1
2
public class OrderApplication { ... }编写Feign客户端的接口
1
2
3
4
5//服务名称
public interface UserClient {
User findById( Long id);
}基于SpringMVC的注解来声明远程调用的信息,例如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
用Feign客户端代替RestTemplate
1
2
3
4
5
6
7
8
9
10
11
12
private UserClient userClient; //注入Feign客户端接口
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.用Feign远程调用
User user = userClient.findById(order.getUserId());
// 3.封装数据
order.setUser(user);
// 4.返回
return order;
}

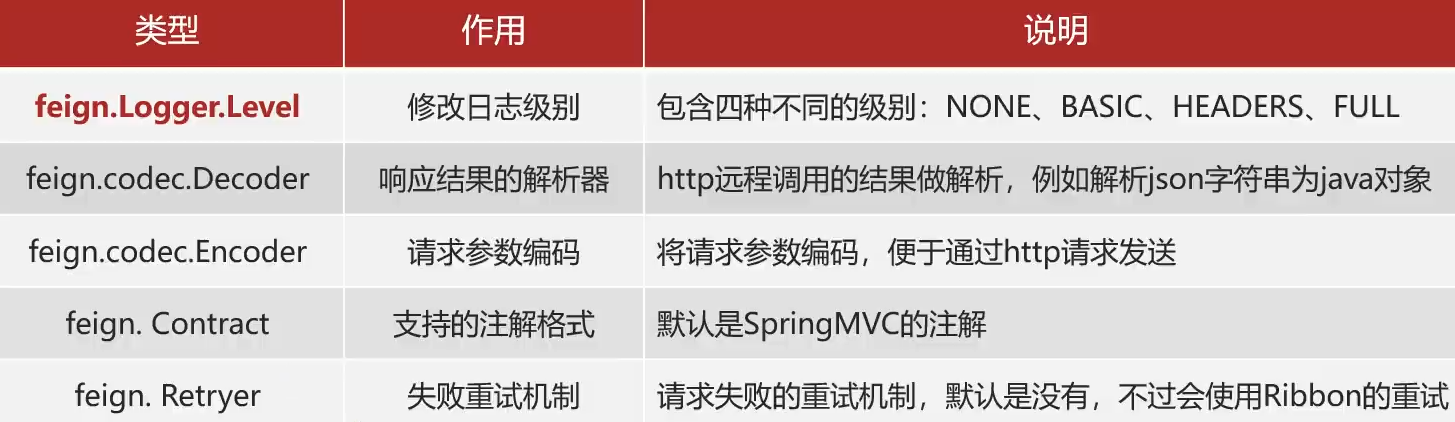
自定义Feign的配置
Feign运行自定义配置来覆盖默认配置,可以修改的配置如下:
方式一:配置文件的方式
全局生效
1
2
3
4
5feign:
client:
config:
default: #对于所有的feign客户端生效
loggerLevel: FULL局部生效
1
2
3
4
5feign:
client:
config:
userservice: #只对userservice的feign客户端生效
loggerLevel: FULL
方式二:Java代码的方式,需要声明一个Bean
1 | public class DefaultFeignConfiguration { |
全局配置:把配置类的class放到启动类的
@EnableFeignClients注解中1
局部配置:把配置类的class放到某个Feign客户端的
@FeignClient注解中1

Feign的性能优化
- Feign底层的客户端实现:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient:支持连接池
- OKHttp:支持连接池
- 优化Feign的性能主要包括:
- 使用连接池代替默认的URLConnection
- 日志级别最好用BASIC或NONE
步骤:
引入HttpClient依赖
1
2
3
4
5<!--HttpClient-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>配置连接池
1
2
3
4
5feign:
httpclient:
enabled: true #支持httpclient的开关
max-connections: 200 #最大连接数
max-connections-per-route: 50 #单个路径的最大连接数

Feign的最佳实践
方式一(继承):给消费者的FeignClient和提供者的Controller定义统一的父接口作为标准

方式二(抽取):将FeignClient抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块,提供给所有消费者使用
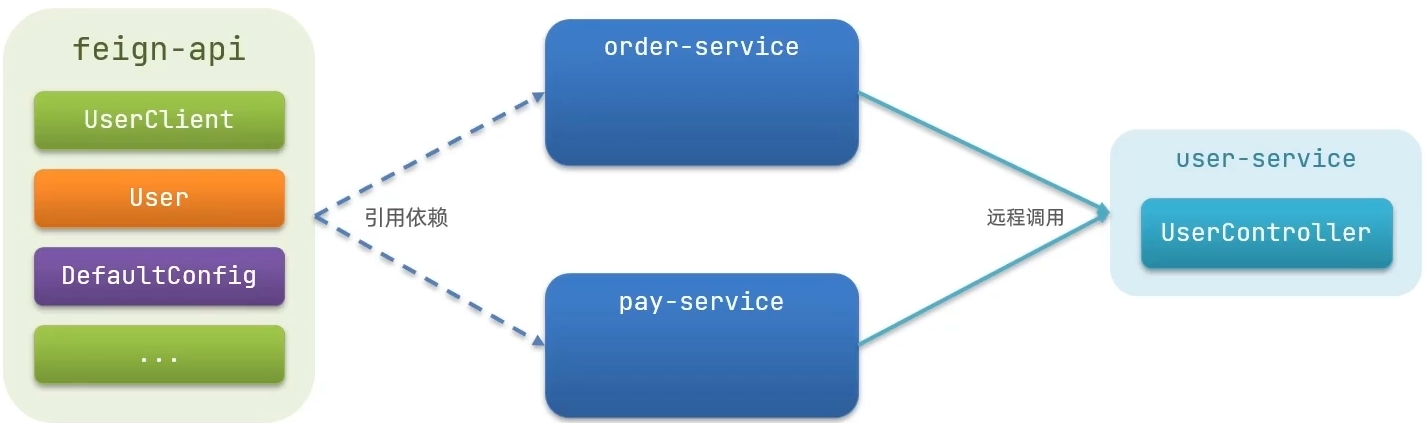

实现方式二(抽取FeignClient):
新建一个module,命名为
feign-api,然后引入feign的starter起步依赖1
2
3
4
5
6<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
</dependencies>将service中编写的FeignClient、POJO、DefaultFeignConfiguration复制到
feign-api项目中
在service中引入编写好的
feign-api依赖1
2
3
4
5
6<!--自己写的feign-api-->
<dependency>
<groupId>cn.itcast.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>修改service中与上述三个组件相关的import部分,改为从
feign-api依赖中引入
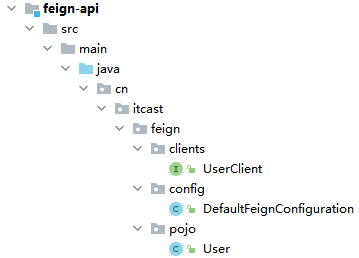

此时启动service会导致引入的FeignClient客户端Bean无法被自动装载
原因:引入的
feign-api依赖下的FeignClient客户端位于cn.itcast.feign.clients包下,不属于当前service的@SpringBootApplication默认扫描包范围解决方法:
方式一:指定FeignClient所在包
1
方式二:指定FeignClient的字节码
1


Gateway服务网关
网关的功能
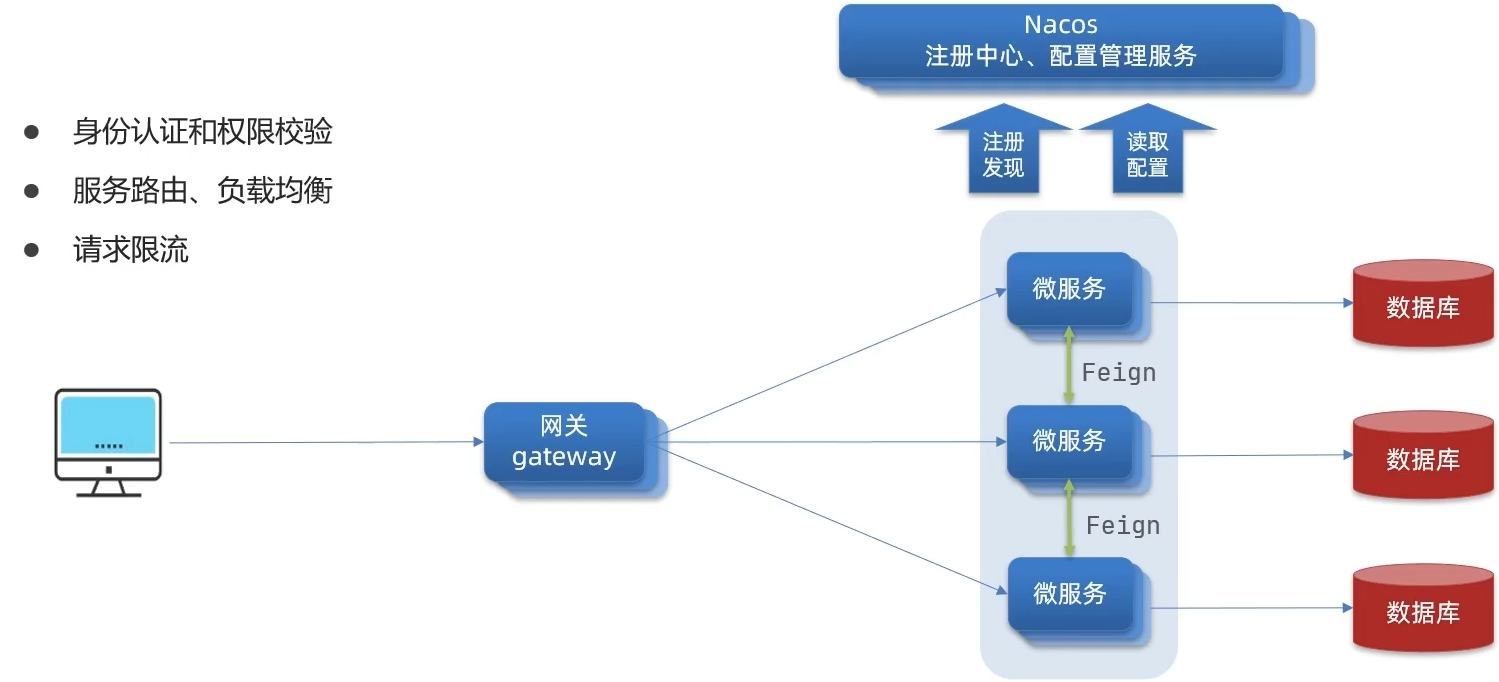
网关技术的实现
在SpringCloud中网关的实现包括两种:
- Gateway
- Zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloud Gateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能

快速入门:搭建网关
创建新的module,引入SpringCloud Gateway的依赖和Nacos依赖,创建网关的SpringBoot启动类
1
2
3
4
5
6
7
8
9
10
11
12<dependencies>
<!--Nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>编写路由配置以及nacos地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18server:
port: 10100
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:80 #nacos地址
gateway:
routes:
- id: user-service #路由标识
uri: lb://userservice #路由的目标地址
predicates: #断言,判断请求是否符合规则
- Path=/user/** #断言是否是以/user/开头的请求
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**启动访问
http://localhost:10100/user/{id}或者http://localhost:10100/order/{orderId}即可
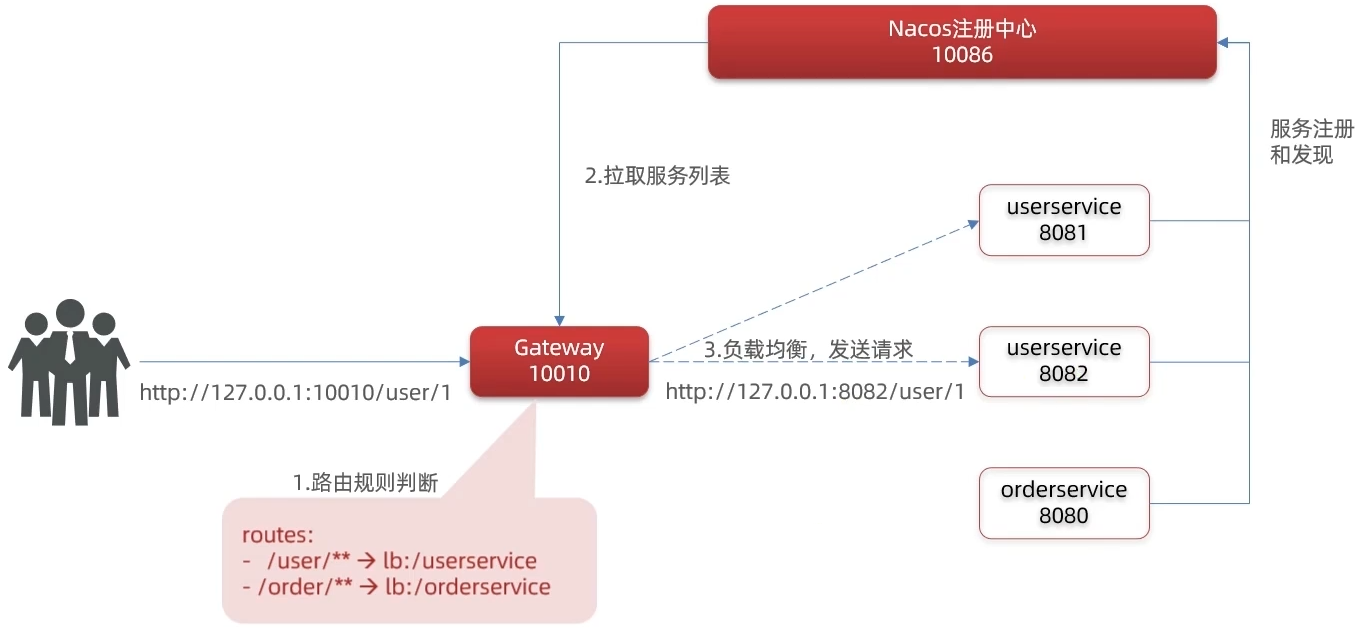

路由断言工厂:Route Predicate Factory
网关路由可以配置的内容包括:
- 路由id:路由的唯一标识
- uri:路由目的地,支持lb(负载均衡)和http两种
- predicates:路由断言,判断请求是否符合要求,符合则转发到路由目的地
- filters:路由过滤器,处理请求或响应
我们再配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转为路由判断条件
例如:Path=/user/**是按照路径匹配,这个规则是由类:org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory处理
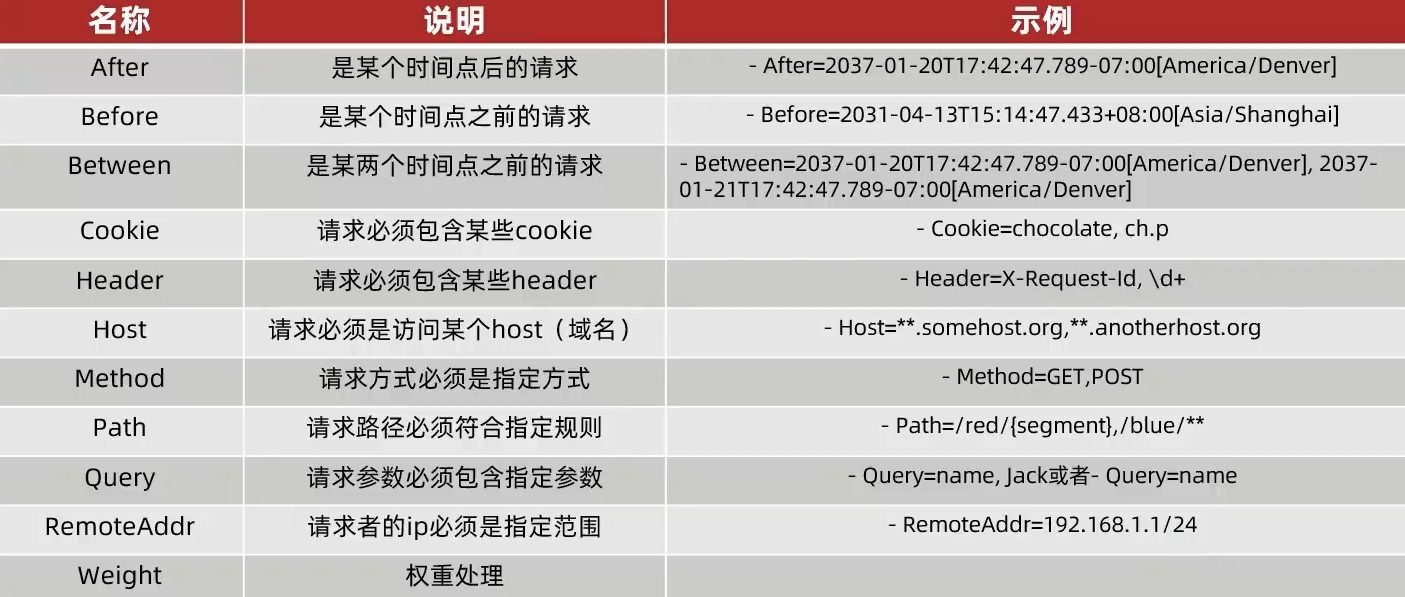
像这样的断言工厂还有:
组合断言:使用多个断言,如果不满足其中一个那么无法路由(404)
1 | spring: |
路由过滤器:GatewayFilter
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理
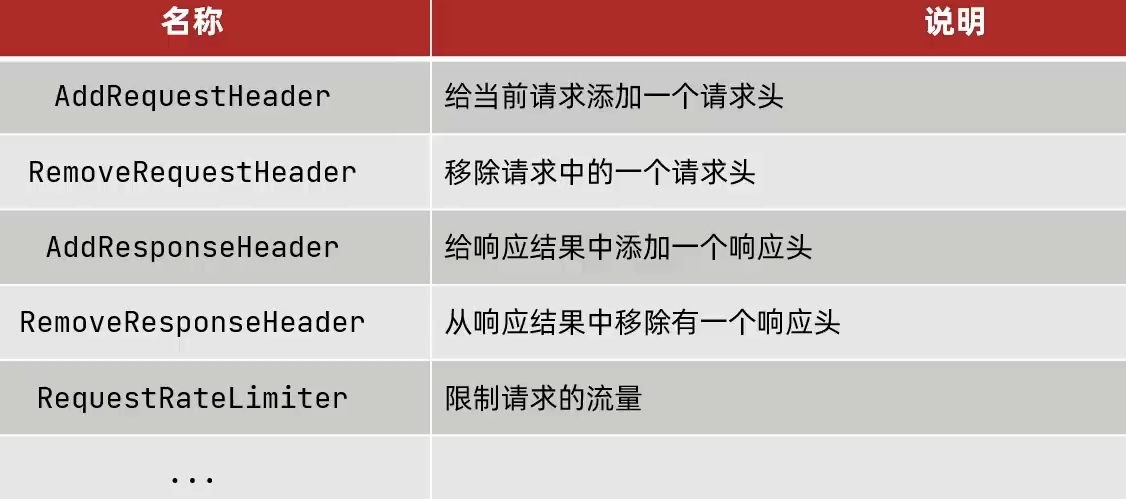
过滤器工厂GatewayFilterFacotry
Spring提供了31种不同的路由过滤器工厂:
案例:给所有进入userservice的请求添加一个请求头:TAOYYZ=likeccz
实现方式:在gateway的SpringBoot核心配置文件中给userservice的路由添加过滤器
1 | spring: |
默认过滤器:如果要对所有的路由都生效此过滤器,则可以将过滤器工厂写到default-filters下:
1 | spring: |
全局过滤器:GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样
区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码实现
定义方式:实现GlobalFilter接口
1 | public interface GlobalFilter { |
案例:定义全局过滤器,拦截并判断用户身份
需求:定义全局过滤器,判断请求参数是否满足以下条件
- 参数中有lover
- lover参数值为ccz
如果满足则放行,否则拦截
实现:定义一个全局过滤器的实现类,实现filter()方法,并且指定为Spring组件,并定义Order执行顺序
1 | //标记为Spring的Bean |
此时访问http://localhost:10100/order/101会被拦截并返回401状态码,因为参数没有lover=ccz

过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter合并到一个过滤器链中,排序后依次执行每个过滤器
- 当前路由过滤器和
DefaultFilter都属于GatewayFilter GlobalFilter通过GatewayFilterAdapter适配成GatewayFilter
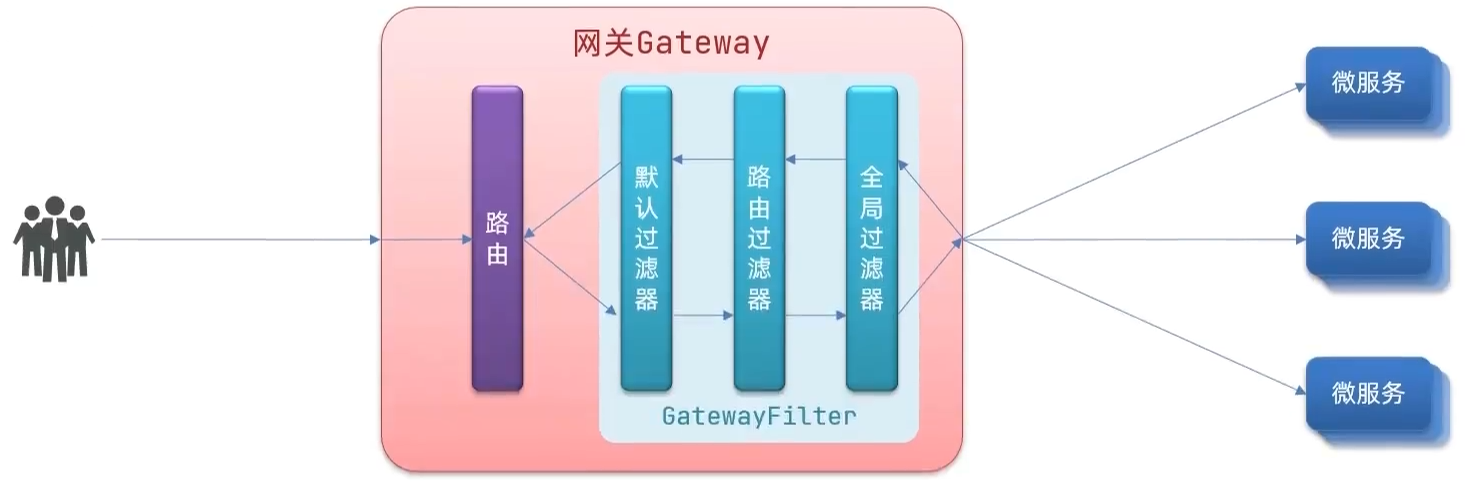
排序:
- 每一个过滤器都必须指定一个int类型的Order值,Order值越小,优先级越高,执行顺序越靠前
- GlobalFilter通过实现Ordered接口或@Order注解来指定Order值,由我们自己指定
- 路由过滤器和DefaultFilter的Order值由Spring指定,默认是按照声明顺序从1开始递增
- 当过滤器的Order值一样时:DefaultFilter > 路由过滤器 > GlobalFilter


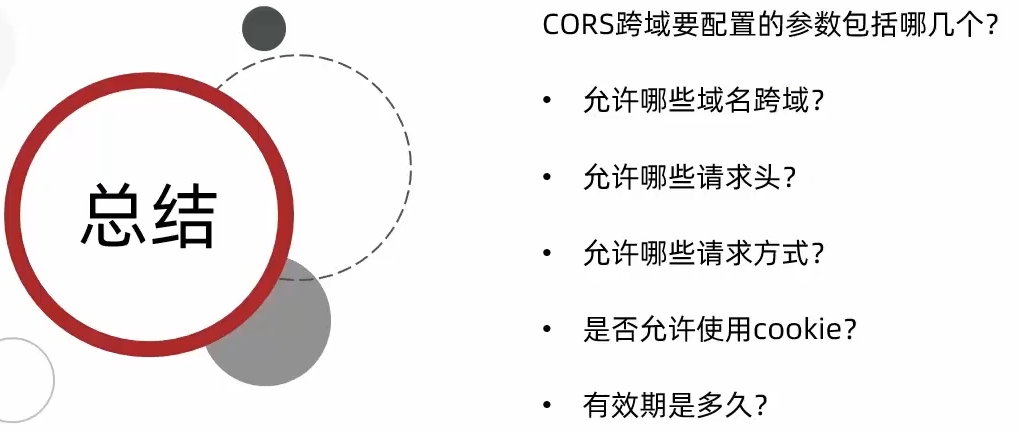
跨域问题处理
跨域是域名不一致,主要包括:
- 域名不同:
www.taobao.com和www.taobao.org - 域名相同,端口不同:
localhost:8081和localhost:8081
跨域问题:浏览器禁止请求的发起者与服务器端发生跨域的AJAX请求,请求被浏览器拦截的问题
解决方案:CORS
网关处理跨域采用的是CORS方案,只需要简单配置即可实现:
1 | spring: |
RabbitMQ消息队列
同步和异步
同步调用存在的问题
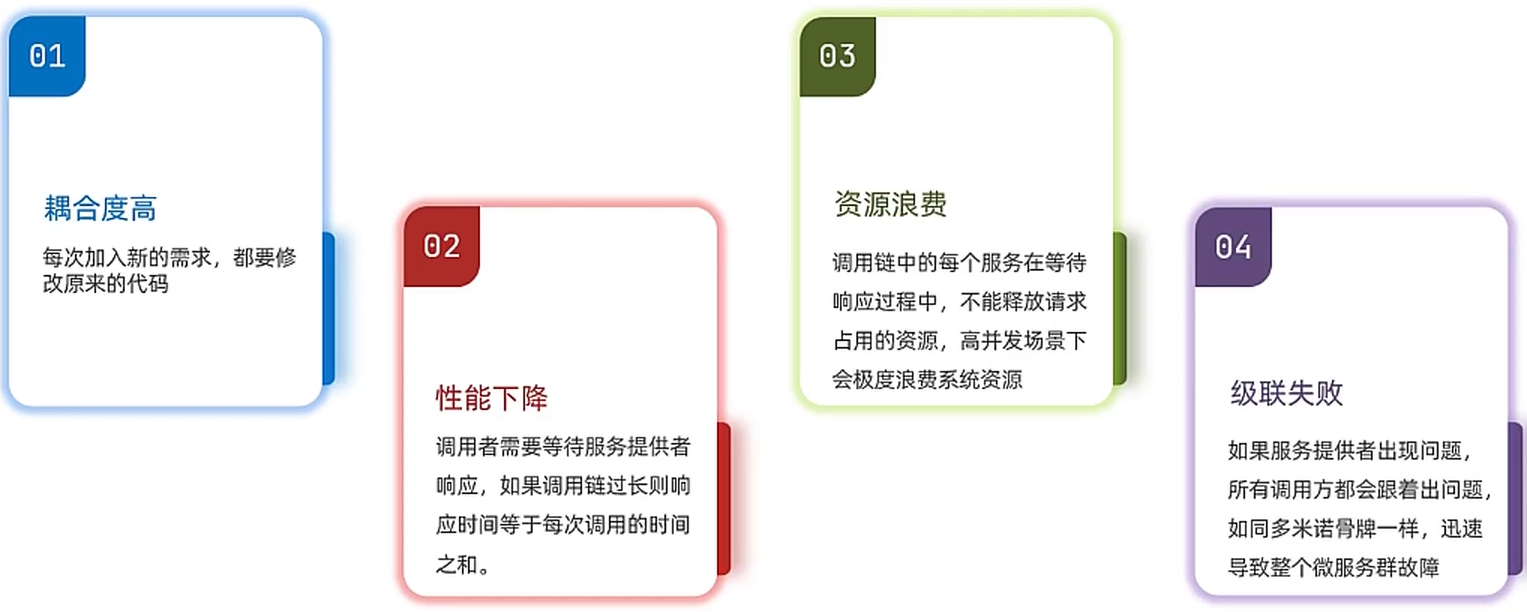
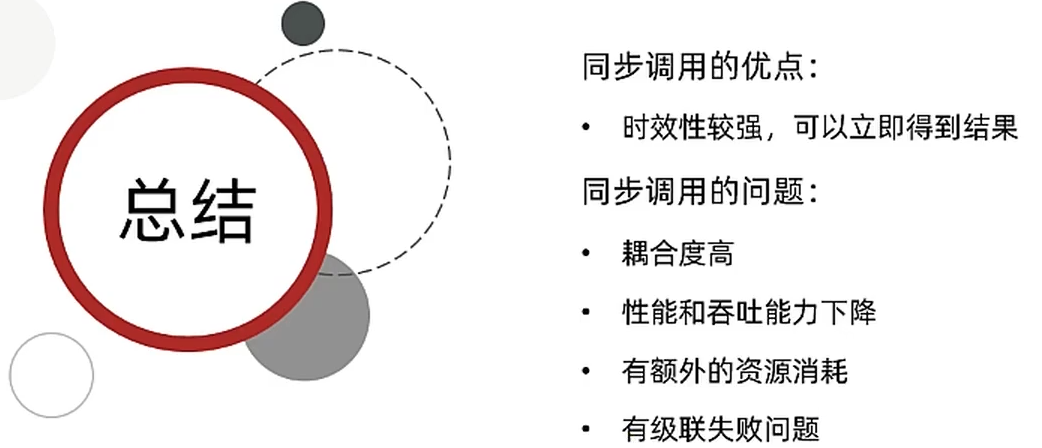
异步调用方案
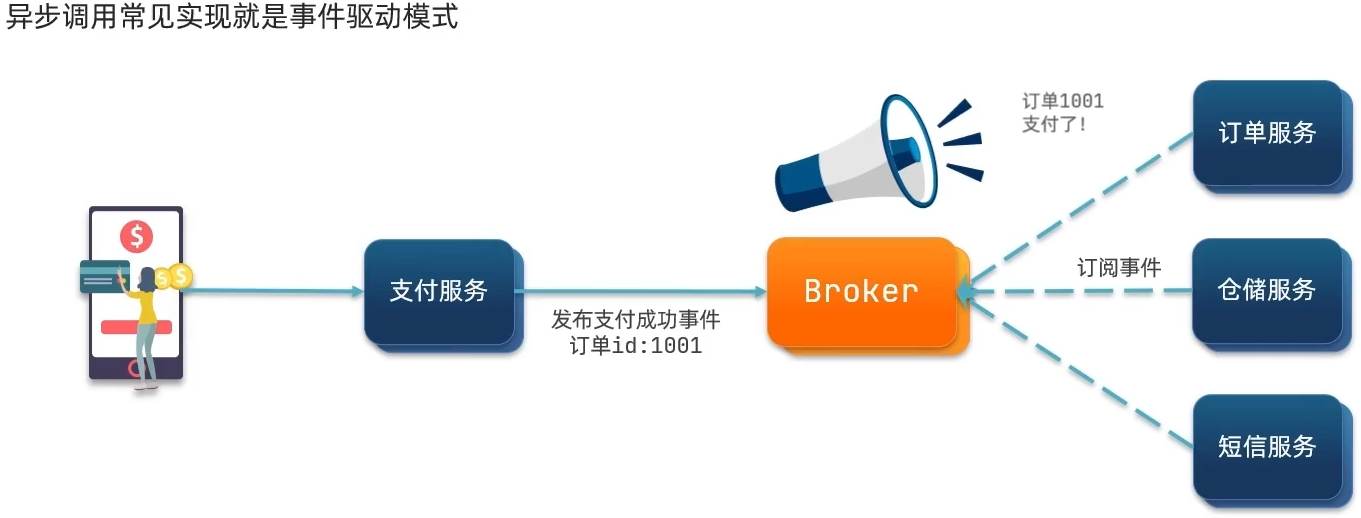
事件驱动优势
服务解耦
性能提升,吞吐量提高
服务没有强依赖,不担心级联失败问题
流量削峰
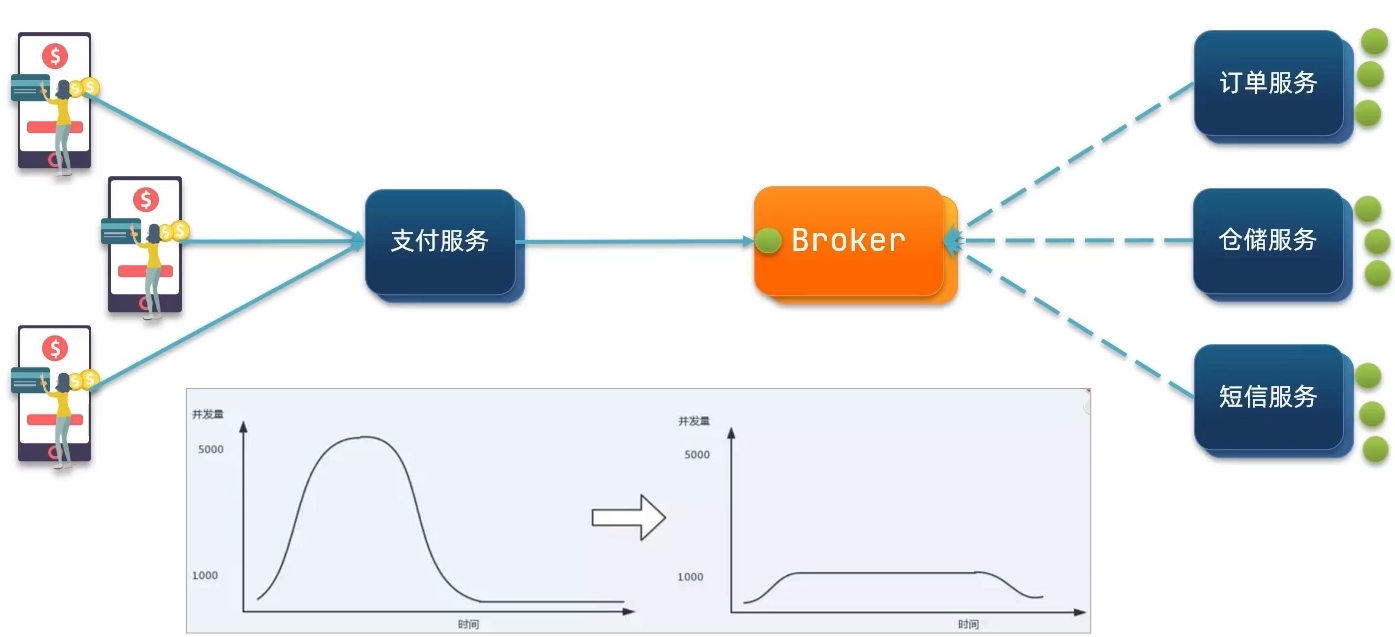

常用的消息队列
MQ(MessageQueue)消息队列,字面上来看就是存放消息的队列。也就是事件驱动架构中的Broker
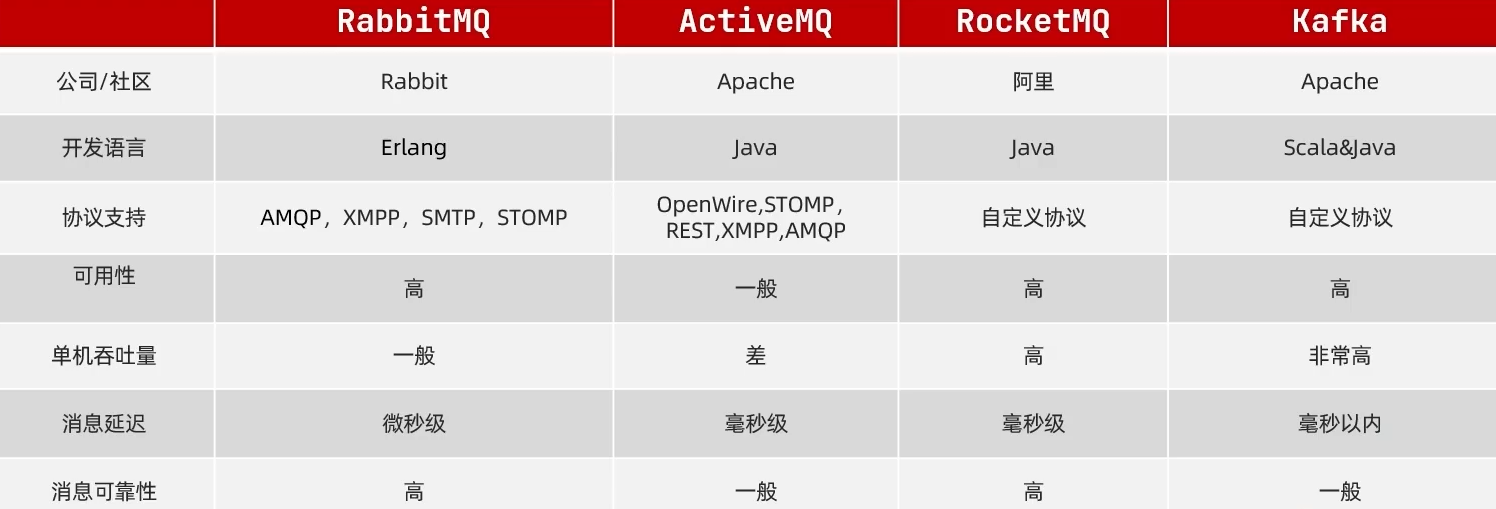
RabbitMQ
RabbitMQ是基于Erlang语言开发的开源消息通信中间件
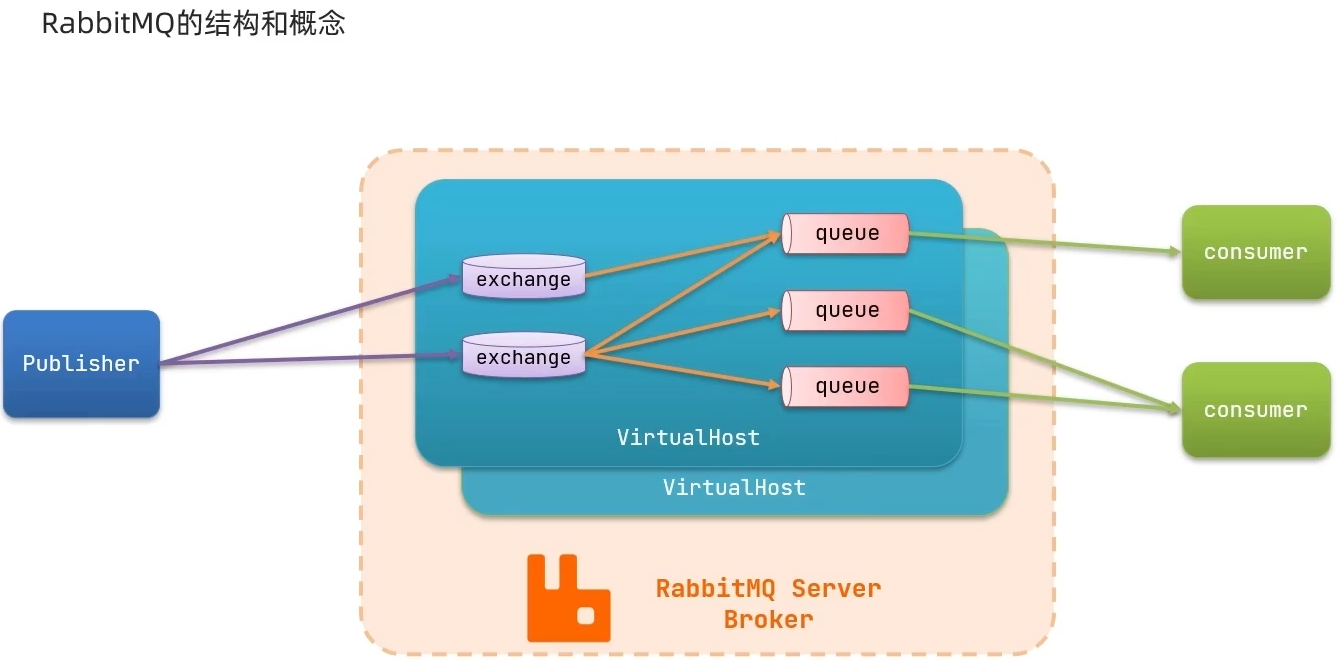

安装RabbitMQ
单机部署:
加载RabbitMQ镜像到docker:
- 在线拉取:
docker pull rabbitmq:3-management - 从本地加载镜像的tar包:
docker load -i mq.tar
- 在线拉取:
运行RabbitMQ到容器:
1
2
3
4
5
6
7
8
9docker run \
-e RABBITMQ_DEFAULT_USER=account \
-e RABBITMQ_DEFAULT_PASS=password \
--name mq \
--hostname mq1 \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3-management
常见消息模型
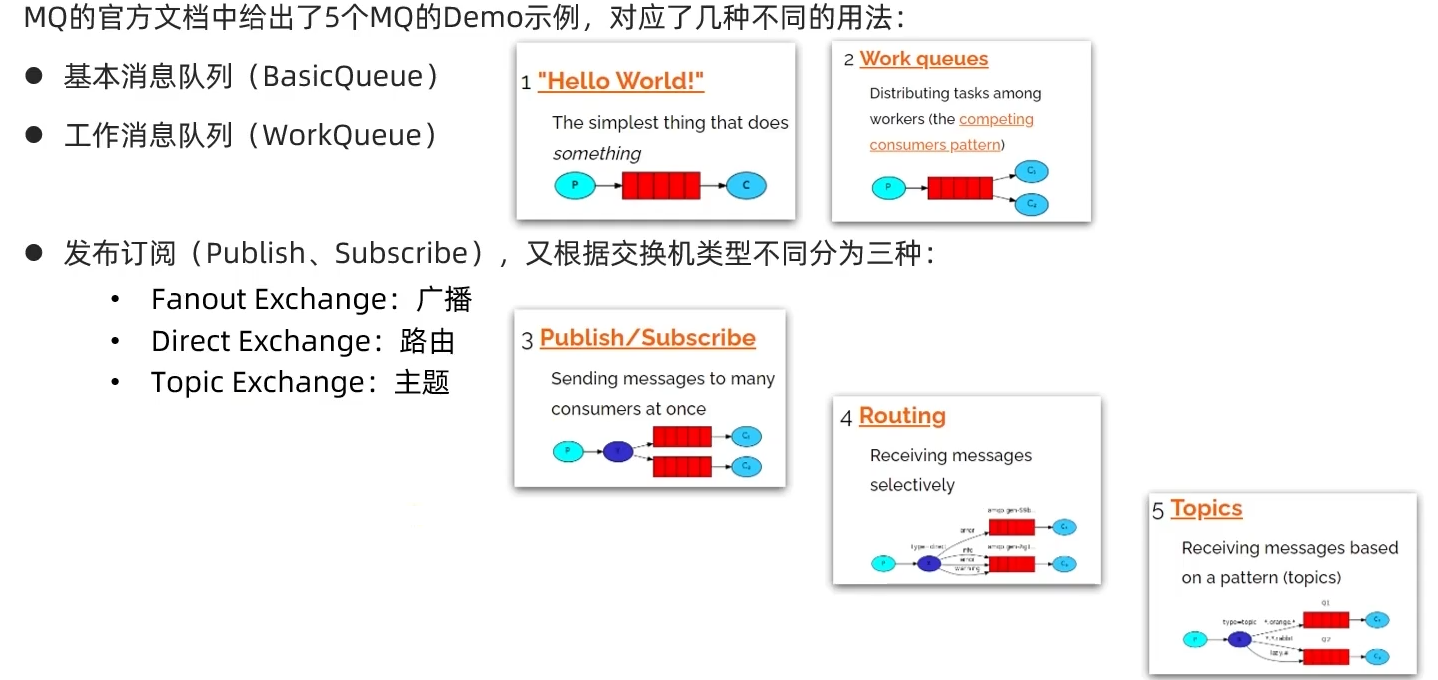
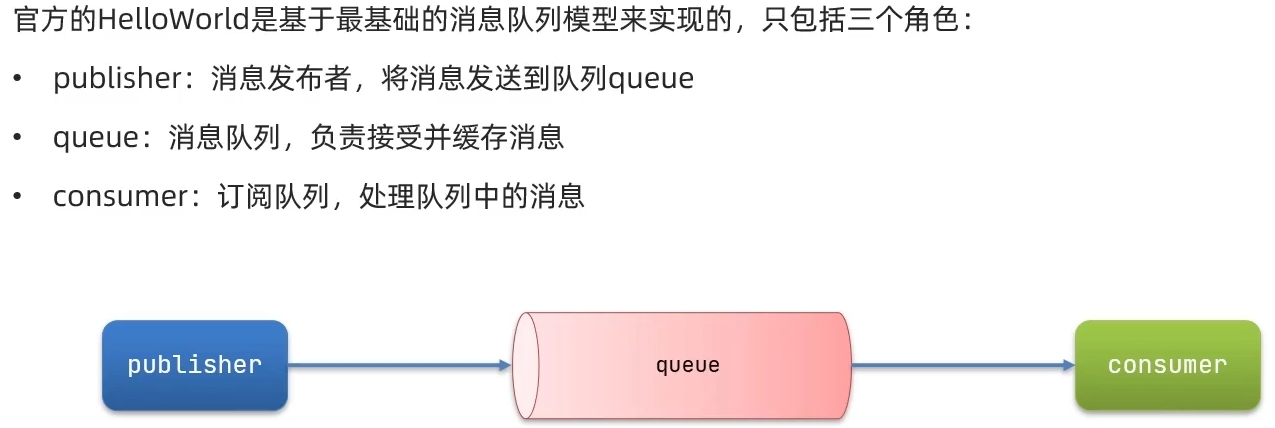
1. HelloWorld案例——简单队列模型
SpringAMQP
概念

快速入门
案例:利用SpringAMQP实现HelloWorld中的简单队列模型的基础消息队列功能
在父工程中引入spring-amqp的起步依赖
1
2
3
4
5<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>在publisher服务中利用RabbitTemplate发送消息到simple.queue这个队列
在publisher服务的SpringBoot核心配置文件中配置mq连接信息:
1
2
3
4
5
6
7spring:
rabbitmq:
host: 192.168.220.12 #RabbitMQ主机,默认localhost
port: 5672 #端口,默认为5672,如果启用SSL,则为5671
virtual-host: / #虚拟主机
username: itcast #默认guest
password: 12345 #默认guest在publisher服务中新建一个类来测试方法
1
2
3
4
5
6
7
8
9
10
11
public class SpringAmqpTest {
private RabbitTemplate rabbitTemplate;
public void test() {
String queueName = "simple.queue";
String message = "hello springAmqp by taoyyz2";
rabbitTemplate.convertAndSend(queueName,message);
}
}
在consumer服务中编写消费逻辑,绑定simple.queue这个队列
在consumer服务的SpringBoot核心配置文件中配置mq连接信息:
1
2
3
4
5
6
7spring:
rabbitmq:
host: 192.168.220.12 #RabbitMQ主机,默认localhost
port: 5672 #端口,默认为5672,如果启用SSL,则为5671
virtual-host: / #虚拟主机
username: itcast #默认guest
password: 12345 #默认guest在consumer服务中新建一个消息监听器类(注册为Bean),编写消费逻辑:
1
2
3
4
5
6
7
public class SpringAmqpListenerTest {
public void listenSimpleQueueMessage(String msg) {
System.out.println("接受到的消息:" + msg);
}
}


2. Work Queue工作队列
工作队列可以提高消息处理速度,避免队列消息堆积
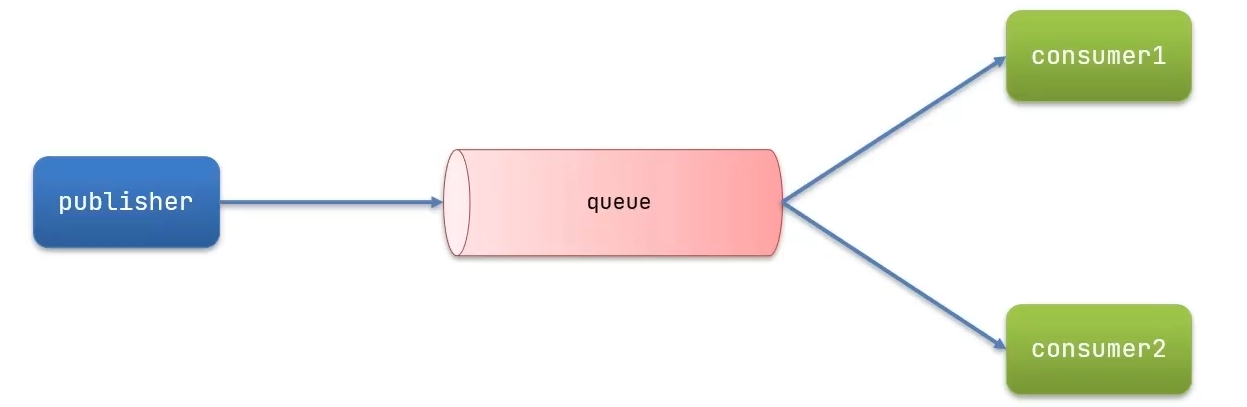
案例:模拟Work Queue,实现一个队列绑定多个消费者
思路:
在publisher服务中定义测试方法,每秒产生50条消息,发送到simple.queue
1
2
3
4
5
6
7
8
9
10
public void test2() throws InterruptedException {
String queueName = "simple.queue";
String message = "hello springAmqp__";
for (int i = 0; i < 50; i++) {
rabbitTemplate.convertAndSend(queueName, message + i + " ");
Thread.sleep(20);
}
System.out.println("推送消息完成");
}在consumer服务中定义两个消息监听者,都监听simple.queue队列
消费者1每秒处理50条消息,消费者2每秒处理10条消息
1
2
3
4
5
6
7
8
9
10
11
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("【1】接受到的消息是:" + msg + LocalTime.now());
Thread.sleep(20);
}
public void listenSimpleQueueMessage2(String msg) throws InterruptedException {
System.err.println("【2】接受到的消息是:" + msg + LocalTime.now());
Thread.sleep(100);
}
问题:由于消费者2处理能力差,在获取消息时与消费者1都分别预取了25条消息,导致消费者2消费25条消息需要大量的时间
消费预取限制
修改SpringBoot核心配置文件,设置preFetch值,可以控制预取消息的上限:
1 | spring: |

发布(Publish)、订阅(Subscribe)
发布订阅模式与之前的区别就是允许将同一消息发送给多个消费者,实现方式是加入了exchange(交换机)
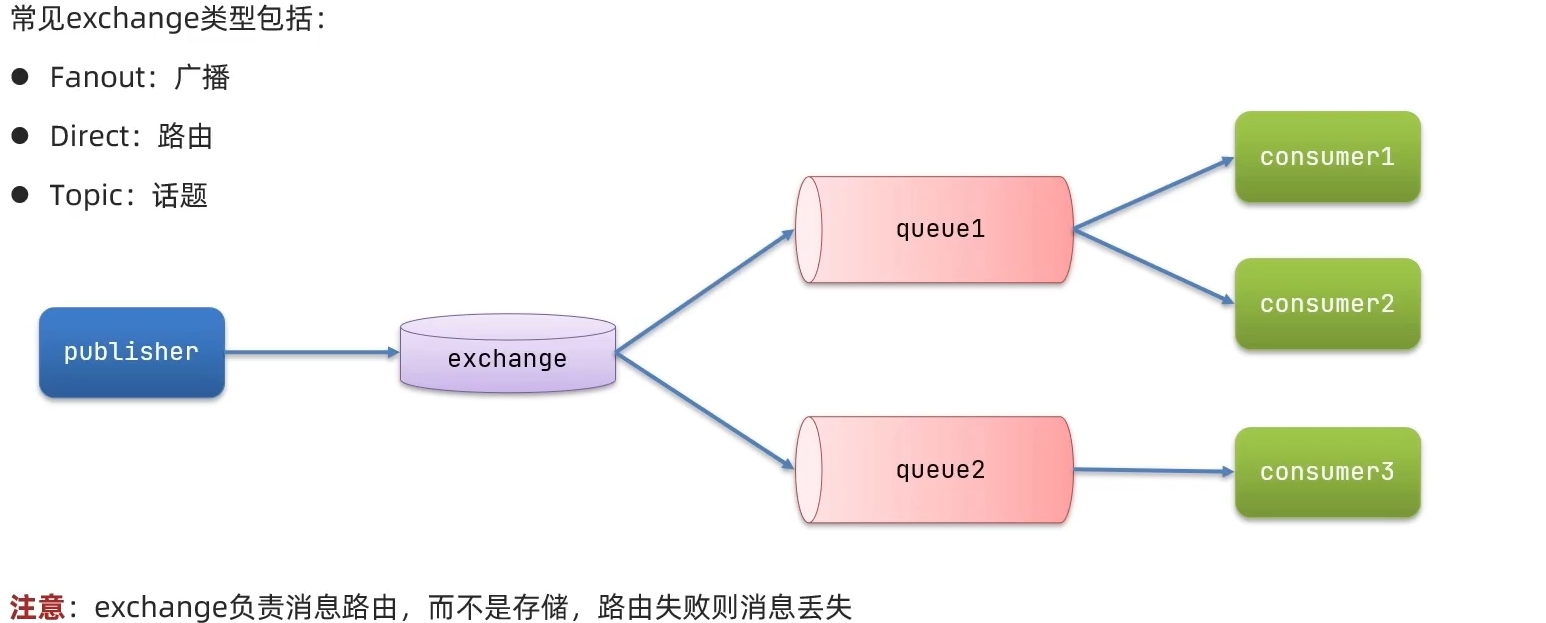
3. FanoutExchange
Fanout Exchange会将接受到的消息路由到每一个跟其绑定的queue,称为广播模式
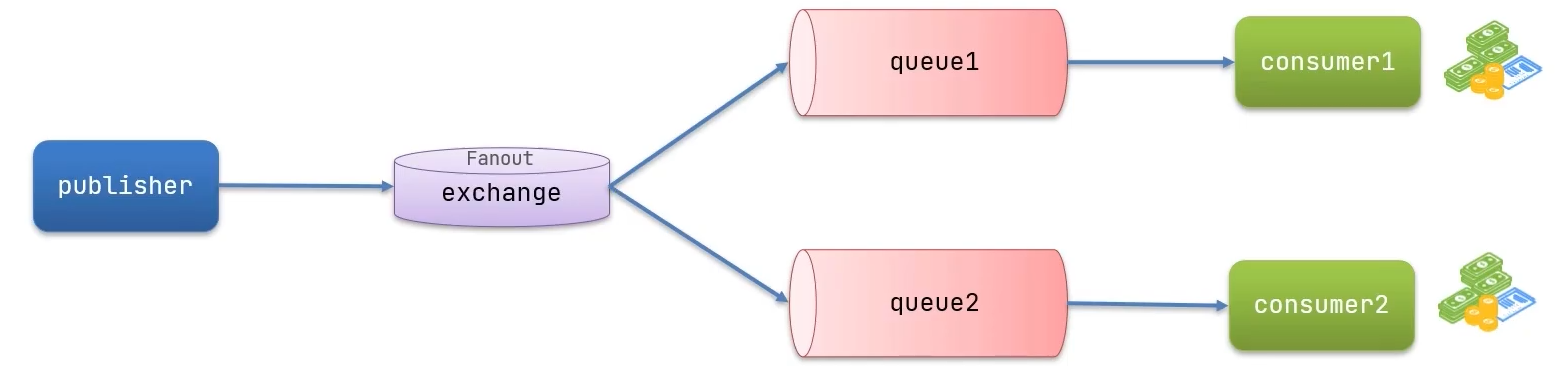
案例:利用SpringAMQP演示FanoutExchange的使用
思路:

在consumer服务中,利用代码声明队列、交换机,并将两者绑定
在consumer服务中声明Exchange、Queue、Binding
SpringAMQP提供了声明交换机、队列、绑定关系的API,例如:
在consumer服务中编写一个配置类,用于产生FanoutExchange、Queue和绑定关系对象Binding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class FanoutConfig {
public FanoutExchange fanoutExchange() {
//产生交换机Bean
return new FanoutExchange("test.fanout");
}
public Queue fanoutQueue1() {
//产生第一个队列的Bean
return new Queue("fanout.q1");
}
public Queue fanoutQueue2() {
//产生第二个队列的Bean
return new Queue("fanout.q2");
}
public Binding fanoutBinding1() {
//绑定队列1到交换机,这里可以通过调方法的返回值获取队列和交换机
return BindingBuilder.bind(fanoutQueue1()).to(fanoutExchange());
}
public Binding fanoutBinding2(Queue fanoutQueue2,FanoutExchange fanoutExchange) {
//绑定队列2到交换机,这里通过参数注入这俩Bean
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
1
2
3
4
5
6
7
8
9
public void listenSimpleQueueMessage3(String msg) {
System.out.println("【queue1】接受到的消息是:" + msg + LocalTime.now());
}
public void listenSimpleQueueMessage4(String msg) {
System.err.println("【queue2】接受到的消息是:" + msg + LocalTime.now());
}在publisher中编写测试方法,向交换机发送消息
1
2
3
4
5
6
7
8
9
10
public void testSendFanoutExchange() {
//交换机名称
String exchangeName = "test.fanout";
//消息
String msg = "hello,everyOne!";
//发送消息
rabbitTemplate.convertAndSend(exchangeName,"", msg);
System.out.println("发送完成!");
}踩坑!!!交换机无法接收到publisher中推送的消息,消费者也无法订阅到消息
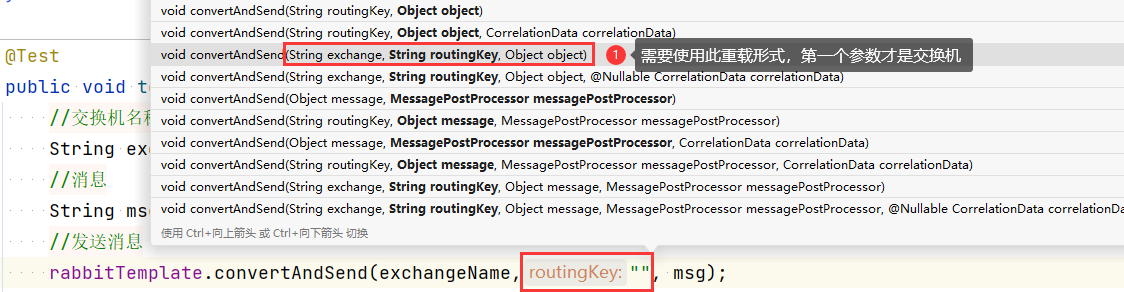
原因:RabbitTemplate对象的
convertAndSend()方法选择了错误的重载:

4. DirectExchange
Direct Exchange会将接受到的消息根据规则路由到指定的Queue,称为路由模式(routes)
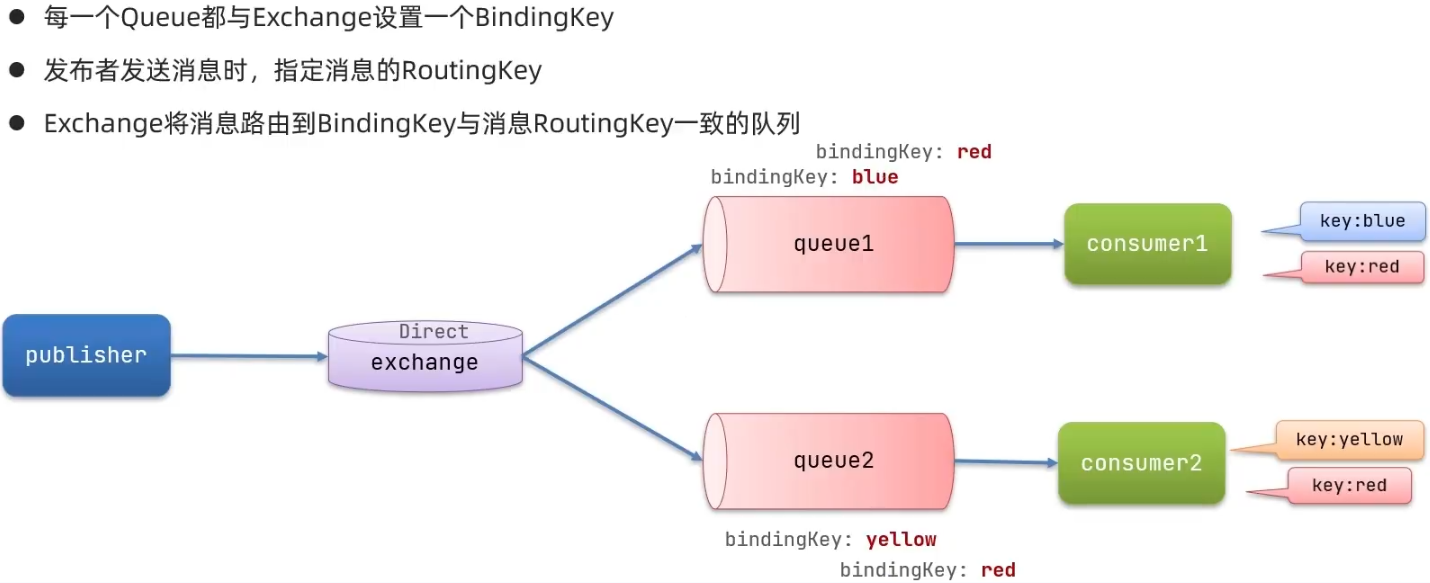
案例:利用SpringAMQP演示DirectExchange的使用
思路:
利用@RabbitListener声明Exchange、Queue、routingKey,代码同下一步
在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public void listenDirectQueue1(String msg) {
System.out.println("【queue1】接受到的消息是:" + msg);
}
public void listenDirectQueue2(String msg) {
System.out.println("【queue2】接受到的消息是:" + msg);
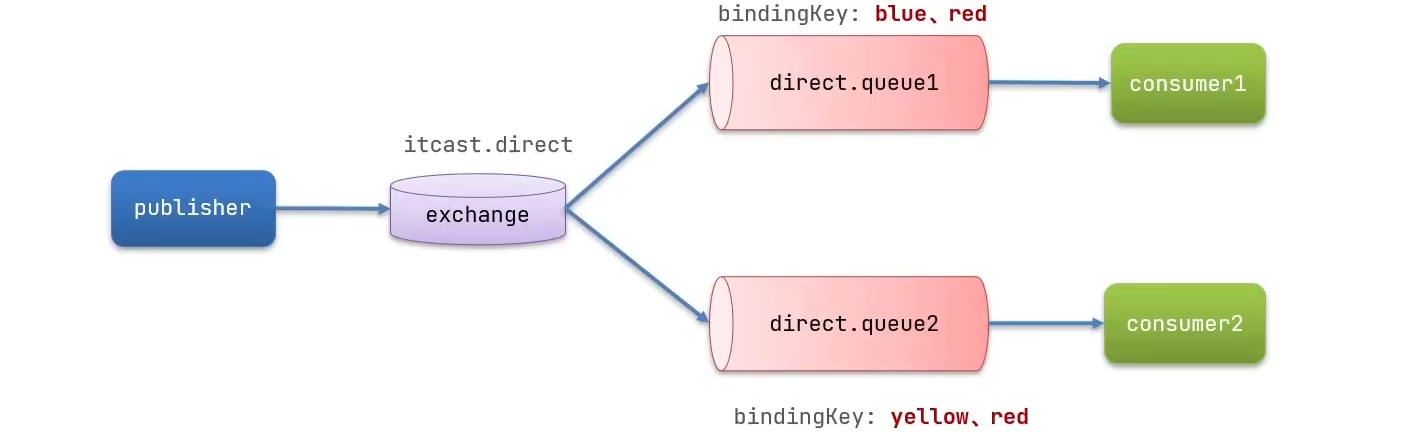
}在publisher中编写测试方法,向itcast.direct发送消息
1
2
3
4
5
6
7
public void testSendDirectExchange() {
String exchangeName = "itcast.direct";
String msg = "hello direct!!";
rabbitTemplate.convertAndSend(exchangeName, "red", msg); //监听了red的routingKey的队列均可收到
System.out.println("发送完成!");
}

5. TopicExchange
TopicExchange的routingKey必须是多个单词的列表,并且以
.分隔Queue与Exchange指定BindingKey时可以使用通配符:
#:代表0个或多个单词
*:代表一个单词
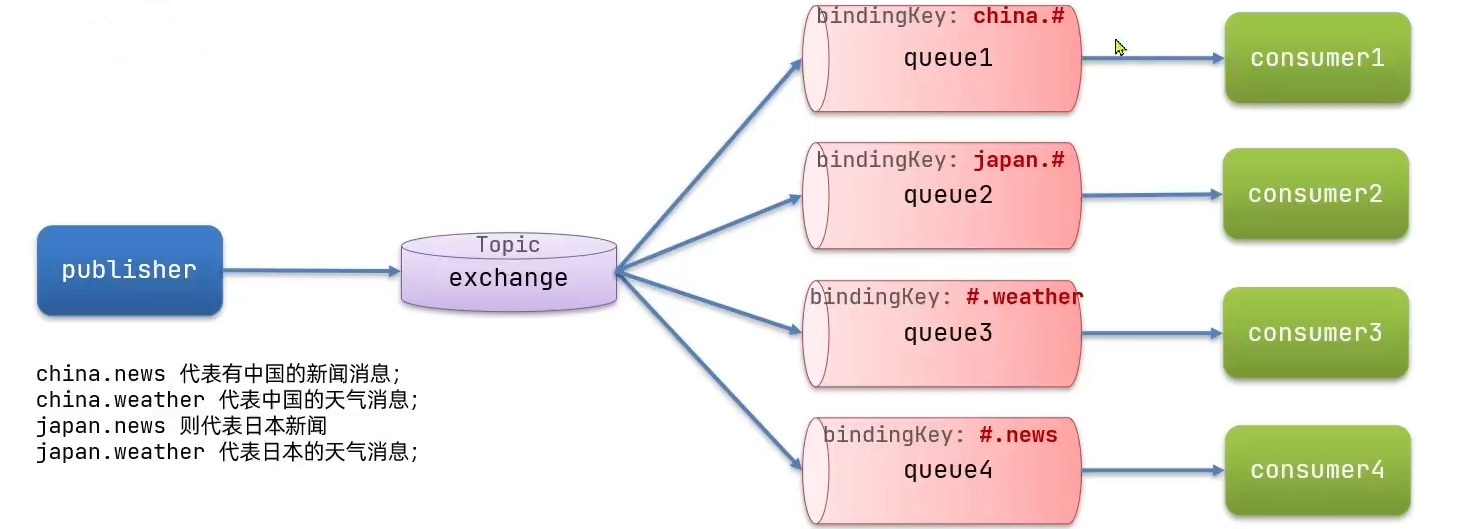
案例:利用SpringAMQP演示TopicExchange的使用
思路:
利用@RabbitListener声明Exchange、Queue、routingKey,代码同下一步
在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public void listenTopicQueue1(String msg) {
System.out.println("【topic.q1】接受到的消息是:" + msg);
}
public void listenTopicQueue2(String msg) {
System.out.println("【topic.q2】接受到的消息是:" + msg);
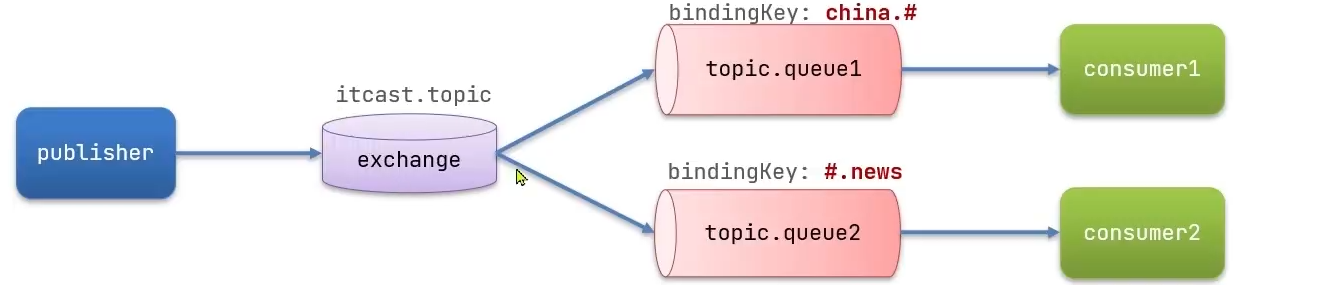
}在publisher中编写测试方法,向itcast.topic发送消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public void testSendTopicExchange() {
String exchangeName = "itcast.topic";
String msg = "hello topic china!!";
// china.# 和 #.news都能收到
rabbitTemplate.convertAndSend(exchangeName, "china.news", msg);
// china.# 能收到
rabbitTemplate.convertAndSend(exchangeName, "china.whether", msg);
// #.news 能收到
rabbitTemplate.convertAndSend(exchangeName, "japan.news", msg);
System.out.println("发送完成!");
}
消息转换器
在SpringAMQP的发送方法中,消息的类型是Object,也就是说可以发送任意对象的消息,SpringAMQP会序列化为字节后发送
Spring对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的
而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。这种方式性能较差。
自定义MessageConverter的Bean即可,推荐使用json序列化:
发送消息:
在publisher服务中引入jackson依赖:
1
2
3
4
5<!--jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>在publisher服务中声明MessageConverter的Bean,使得发送消息时可以以JSON格式发送
1
2
3
4
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}在publisher服务中发送消息:
1
2
3
4
5
6
7
public void testSendObject() {
Map<String, Object> msg = new HashMap<>();
msg.put("name", "菜菜子");
msg.put("age", 21);
rabbitTemplate.convertAndSend("object.queue",msg);
}
接收消息:
在consumer服务中也引入jackson依赖
在consumer服务中声明MessageConverter的Bean,使得接受消息时可以以JSON格式解析
1
2
3
4
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}在consumer服务中定义一个监听者监听队列接收消息
1
2
3
4
public void listenObjectQueue(Map<String, Object> msg) {
msg.forEach((s, o) -> System.out.println(s + " --> " + o));
}
